STREAM: Sustainable Memory Bandwidth in High Performance Computers
|
John D. McCalpin, Ph.D.
john@mccalpin.com
"Dr. Bandwidth"
|
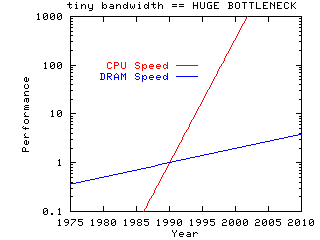
|
|
|
|
Here are the RESULTS!
Top 20 Results for Shared-Memory Systems!
This set of results includes the top 20 shared-memory systems
(either "standard" or "tuned" results), ranked by STREAM TRIAD
performance. Like the LINPACK NxN benchmark, this is intended
to show off the best possible bandwidth of these large systems.
The results are currently presented in the following
tables:
Standard Results
The "standard" set of results presents the results of the C or Fortran
versions of the STREAM benchmark running with 64-bit data types on production
hardware. The "standard" set of results excludes:
-
Cases with 32-bit operands or operations.
-
Cases with significantly modified code or assembly language.
-
Simulated results.
-
Results from experimental or non-production hardware or software.
The results are currently presented in the following tables:
Tuned Results
The "tuned" set of results presents the results of the
STREAM benchmark running with 64-bit data types on production
hardware, but allows code modification (including assembly
language coding). The "tuned" set of results excludes:
-
Cases with 32-bit operands or operations.
-
Simulated results.
-
Results from experimental or non-production hardware or software,
or non-standard system configurations.
The results are currently presented in the following tables:
ALL Results sorted by Name
All results are presented in the following tables:
ALL Results sorted by Submission Date
All results are presented in the following tables:
PC-compatible Results
This set of tables shows "standard" results for IBM PC-compatible computers.
This classification is mostly obsolete, and is retained primarily for
historical purposes. These results are all included in the
Standard results tables.
The recommended way to generate "standard" results is to compile the
source code (C and FORTRAN are both equally "official")
following the
run rules and the guidelines
included in the comments at the top of the source code.
The results are currently presented in the following tables:
Experimental/Nonstandard Results
These tables include only results that are
-
Simulated, or
-
Based on experimental or non-production hardware, or
-
Based on partially depopulated systems.
Note:
A "partially depopulated" system is one in which only a subset of the
cpus are used for the benchmark, and for which this subset is spread around
the machine to decrease contention. For example on the SGI Origin2000,
each node has 2 cpus sharing a single bus and memory subsystem. The results
in this table labelled "1 per node" are based on using only one cpu per
node board, and are considered a "nonstandard" way of using the machine.
Similarly, the Sun Ultra10000 has 4 cpus per node board, so results using
1, 2, or 3 cpus per node also go into this table of "nonstandard" results. 
The results are currently presented in the following tables:
MPI Results
These results (typically run on clusters) are based on the STREAM ports
to MPI in either Fortran
(stream_mpi.f)
or C
(stream_mpi.c).
These MPI results are not "standard" when applied to a single SMP system
because they do not enforce the same array alignment that would be obtained
with the linear addressing of the standard version of STREAM -- but they
should give very similar performance in most cases. I do allow these results
in the main ("standard") tables, but mark the entries as being from MPI
implementations.
32-bit Results
These tables include only results with 32-bit operands or operations.
Results using 64-bit operands that move the data in 32-bit "chunks" are
not
here. The results are currently presented in the following tables:
(Obsolete) Macintosh-Compatible Results
This set of tables shows "standard" results for obsolete, pre-Intel (i.e., Motorola 68000
and PowerPC) Macintosh and compatible computers, and is retained for historical purposes only.
These results are all included in the Standard results tables.
Some of these results were based on re-compiling the STREAM source code
while others used the contributed binaries.
The results are presented in the following tables:
Other Obsolete Results
These results have been superceded for one reason or another, but I never
throw anything away (unless it was just plain wrong....).
The STREAM benchmark and web site are the responsibility of
John D. McCalpin john@mccalpin.com
The STREAM website is hosted as a courtesy by the
Department
of Computer Science
School of Engineering and Applied Science
University of Virginia,
Charlottesville, Virginia, USA

