Using Timings for the SWIM Benchmark from the SPEC CPU Suites to Estimate
Sustainable Memory Bandwidth
John D. McCalpin, Ph.D.
john@mccalpin.com
Revised to 2002-12-02
Introduction
It has long been recognized that certain classes of structured-mesh computational
fluid dynamics (CFD) codes are closely correlated with "pure" memory bandwidth.
Indeed, the STREAM benchmark was developed in order to explain the difference
in performance for various computers for my large-scale ocean modelling
applications. This short note discusses the use of published
results with the SWIM benchmark from the SPEC's CPU benchmark suites as
an estimator for sustainable memory bandwidth. SWIM results
are not acceptable for publication as STREAM results, but they are a very
useful indicator of sustainable memory bandwidth on systems for which STREAM
results are not available.
History
The source code for SPEC's version(s) of SWIM is nearly identical
to the "classic" shallow water code written by Paul Swarztrauber, based
on the equations derived by Robert Sadourny and published in the Journal
of Atmospheric Sciences, VOL 32, NO 4, APRIL 1975.
The size of the arrays have been changed and a few vectorization and parallelization
directives have been removed, but (with one major caveat) the code is otherwise
as originally written. The "major caveat" is a small change introduced
while porting the code from the CFP95 suite to the CFP2000 suite that has
a significant influence on the optimization of the code on some platforms.
This will be discussed in more detail below.
Analysis
SWIM is a prototypical vector code -- all of the arrays used by the code
are accessed contiguously (with one significant exception discussed below)
and stream through the processor with a minimal amount of work per element.
In the estimation of the derivatives and spatial averages in the shallow
water equations, many of the arrays are accessed multiple times with small
offsets (no more than one unit in either direction) in each of the two
spatial directions. The analysis below is based on the assumption
that for systems with caches, each array needs to be loaded from memory
only once, and that the other (offset) accesses can be satisfied from the
systems caches. This assumption will be reviewed in detail as I analyze
each section of code.
The SWIM code defines a total of 14 two-dimensional arrays.
For the 102.swim code from CPU95, the dimensions are 513 by 513 and the
elements are "default single-precision real", which occupy four bytes each
on most (perhaps all?) of the systems for which results are published.
For the 171.swim code from CPU2000, the dimensions are 1335 by 1335 and
the elements are "REAL*8", which occupy eight bytes each on all of the
systems for which results are published. So the total
amount of memory required by the major arrays is (14 x 513 x 513 x 4 =
) 14.05 MB for 102.swim and (14 x 1335 x 1335 x 8 = ) 190.36 MB for 171.swim.
In the standard configuration of SWIM, the overwhelming majority of
the execution time and the memory traffic is associated with the execution
of three subroutines, CALC1, CALC2, and CALC3, while in the CPU2000 version
of SWIM (171.swim) the MAIN program must also be included in the execution
profile.
CALC1
CALC1 is dominated by the execution of the following nested loop:
DO J=1,N
DO I=1,M
CU(I+1,J) = .5D0*(P(I+1,J)+P(I,J))*U(I+1,J)
CV(I,J+1) = .5D0*(P(I,J+1)+P(I,J))*V(I,J+1)
Z(I+1,J+1) = (FSDX*(V(I+1,J+1)-V(I,J+1))-FSDY*(U(I+1,J+1)
$ -U(I+1,J)))/(P(I,J)+P(I+1,J)+P(I+1,J+1)+P(I,J+1))
H(I,J) = P(I,J)+.25D0*(U(I+1,J)*U(I+1,J)+U(I,J)*U(I,J)
$ +V(I,J+1)*V(I,J+1)+V(I,J)*V(I,J))
END DO
END DO
where both "N" and "M" are set to 1334.
Inspection of the code shows that the minimum memory traffic consists
of reading three arrays (P, U, V) and writing four arrays (CU, CV, Z, H).
On most cached architectures, storing into the four output arrays will
result in those arrays being read into some level of the cache before the
store operations are allowed to complete. This "write allocate"
traffic will be tallied separately in the final analysis.
The assumption that the caches will supply all of the "offset" elements
requires that the available cache be able to hold two rows of P, two rows
of U, and two rows of V, in addition to one row of each of CU, CV, Z, and
H. The total requirement is thus 10 rows of data.
For 102.swim, this is 10 x 513 x 4 = 20.04kB, while for 171.swim, this
is 10 x 1335 x 8 = 104.3 kB. Most, but not all, of the systems
with reported benchmarks results have sufficient cache to justify my modelling
assumption.
Note that if the system's cache is large enough to hold all nine arrays
accessed by CALC3 (at the end of the previous time step), then CALC1 will
find U, V, and P in the cache and will not need to load them from memory.
For 102.swim, this requires that the cache be larger than 9 x 513 x 513
x 4 = 9.04 MB, while for 171.swim this requires that the cache be larger
than 9 x 1335 x 1335 x 8 = 122.4 MB. I am not aware of any
systems with SPECfp95 results that have 9 MB caches, and I am aware of
only one system with published CFP2000 results with a cache larger than
122.4 MB (IBM's POWER4 family). However, the IBM POWER4 cache
is a shared cache, so in throughput runs only a fraction (1/4 or 1/8, depending
on the system) is available to each processor. Caveat Emptor.
CALC2
CALC2 is dominated by the execution of the following nested loop:
DO J=1,N
DO I=1,M
UNEW(I+1,J) = UOLD(I+1,J)+
$ TDTS8*(Z(I+1,J+1)+Z(I+1,J))
$ *(CV(I+1,J+1)+CV(I,J+1)+CV(I,J)+CV(I+1,J))
$ -TDTSDX*(H(I+1,J)-H(I,J))
VNEW(I,J+1) = VOLD(I,J+1)-TDTS8*(Z(I+1,J+1)+Z(I,J+1))
$ *(CU(I+1,J+1)+CU(I,J+1)+CU(I,J)+CU(I+1,J))
$ -TDTSDY*(H(I,J+1)-H(I,J))
PNEW(I,J) = POLD(I,J)-TDTSDX*(CU(I+1,J)-CU(I,J))
$ -TDTSDY*(CV(I,J+1)-CV(I,J))
END DO
END DO
Inspection of the code shows that the minimum memory traffic consists of
reading seven arrays (UOLD, VOLD, POLD, Z, CU, CV, H) and writing three
arrays (UNEW, VNEW, PNEW). As in CALC1, the tree store operations
will result in three additional reads ("write allocates") on most cached
systems.
The assumption that the caches will supply all of the "offset" elements
requires that the available cache be able to hold two rows of Z, two rows
of CU, two rows of CV, and two rows of H, in addition to one two each of
UOLD, VOLD, POLD, UNEW, VNEW, PNEW. The total requirement is
thus 14 rows of data. For 102.swim, this is 14 x 513 x 4 = 28.05kB,
while for 171.swim, this is 14 x 1335 x 8 = 146.02kB. Most,
but not all, of the systems with reported benchmark results have sufficient
cache to justify my modelling assumption.
Note that if the system has adequate cache to hold all seven of the
arrays used in CALC1, then the four arrays written by CALC1 will be in
the cache when CALC2 executes, and will not need to be loaded from memory.
For 102.swim, this requires 7 x 513 x 513 x 4 = 7.03 MB, while for 171.swim
this requires 7 x 1335 x 1335 x 8 = 95.2 MB. There are
a few results from CFP95 with 8 MB caches where this cacheing of results
from CALC1 to CALC2 produces anomalously high results. There is at
least one system with published CFP2000 results where the 128 MB cache
allows cacheing of results from CALC1 to CALC2. Caveat Emptor.
CALC3
CALC3 is dominated by the execution of the following nested loop:
DO J=1,N
DO I=1,M
UOLD(I,J) = U(I,J)+ALPHA*(UNEW(I,J)-2.*U(I,J)+UOLD(I,J))
VOLD(I,J) = V(I,J)+ALPHA*(VNEW(I,J)-2.*V(I,J)+VOLD(I,J))
POLD(I,J) = P(I,J)+ALPHA*(PNEW(I,J)-2.*P(I,J)+POLD(I,J))
U(I,J) = UNEW(I,J)
V(I,J) = VNEW(I,J)
P(I,J) = PNEW(I,J)
END DO
END DO
Inspection of the code shows that the minimum memory traffic consists of
reading 9 arrays (UNEW, VNEW, PNEW, UOLD, VOLD, POLD, U, V, P) and writing
six arrays (U, V, P, UOLD, VOLD, POLD). Because each of the
target (left-hand-side) arrays is also a source (right-hand-side), there
are no "write allocates" associated with the execution of this subroutine.
There are no offsets in either of the spatial indices in this subroutine,
so the caches are only used to source and sink contiguous data, and are
not used to satisfy "offset" references.
Note that if the system has adequate cache to hold all ten of the arrays
used in CALC2, then the three arrays written by CALC2 will be in the cache
when CALC3 executes, and will not need to be loaded from memory.
For 102.swim, this requires 10 x 513 x 513 x 4 = 10.04 MB, while for 171.swim
this requires 10 x 1335 x 1335 x 8 = 135.97 MB. I am not aware
of any systems with published results that exceed these cache sizes, but
I have not done a thorough search. Caveat Emptor.
However, in 171.swim, an extraneous loop is executed in the MAIN program
between calls to CALC2 and CALC3. This is discussed in detail
below. This loop reads UNEW, VNEW, PNEW. If the
cache is large enough to hold these entire arrays, then these will be in
the cache when CALC3 executes and will not need to be loaded from memory.
This only applies to 171.swim, and requires a cache size of 3 x 1335 x
1335 x 8 = 40.8 MB. I am aware of only one family
of systems with cache sizes in this range (IBM's POWER4 family), but other
systems may include caches of sufficient size to negate my counting assumptions.
Caveat Emptor.
MAIN
In the 171.swim code from CFP2000, two changes were made that cause many
systems to spend non-trivial time in the MAIN program.
The MAIN program includes a nested loop which calculates the sum of absolute
values of the UNEW, VNEW, and PNEW arrays. This is not
part of the main calculation, but was added by the original author as a
simple check for numerical instability. In the original
102.swim, this code is executed only twice for the 1710 time steps that
the model is run, so for the purposes of this analysis I will ignore the
bandwidth contribution of that loop. Unfortunately, in the process
of porting the code to CPU2000, the input file for 171.swim was modified
to execute this "checking" code every time step, so it's contribution to
the total memory traffic can not be ignored. To make matters
much worse, an additional assignment statement was added to the source
code to make a simple optimization very complex. The original
source code looked like:
DO ICHECK = 1, MNMIN
DO JCHECK = 1, MNMIN
PCHECK = PCHECK + ABS(PNEW(ICHECK,JCHECK))
UCHECK = UCHECK + ABS(UNEW(ICHECK,JCHECK))
VCHECK = VCHECK + ABS(VNEW(ICHECK,JCHECK))
END DO
END DO
Note that the loops are organized in the "wrong" order for FORTRAN, so
that the memory references are strided rather than contiguous.
This coding style suggests that the code was originally developed for a
Cray vector system, where strided memory accesses run at almost the same
speed as contiguous accesses. Because this was a common coding
style on Cray systems, most compilers for microprocessor-based systems
included optimization features that would reverse the order of these loops
to regain contiguous memory accesses.
Due to SPEC's copyright on their modified code, I will not reproduce
the offending modification here. The source code change consisted
of a modification of one of the elements along the main diagonal of the
array. This modification of one of the source arrays caused
many compilers to refrain from reversing the order of the loops.
Inspection of the data dependence shows that reversing the loops is still
a correct optimization, but it requires an additional level of analysis
that many compilers did not include when CPU2000 was first introduced.
If this set of loops is executed in the stated order, dramatic reductions
in performance are typically observed on cache-based systems.
The strided accesses mean that the system does not obtain the benefit of
spatial locality in loading several data items per cache line, and most
systems also incur TLB misses on each load. So instead of going to
memory once per cache line, most systems had to go to memory twice per
data element -- once for the Page Table Entry and once for the data item.
On a system with 64 Byte cache lines (8 64-bit entities per cache line),
this is a 16x increase in memory traffic relative to the optimal ordering
of the loop. The resulting code requires effectively 48 64-bit words
of memory traffic to satisfy the 3 64-bit words actually required.
This is more than the memory traffic required by the rest of the program,
and this extraneous modification to the SWIM code caused many systems to
more than double their execution time until each vendor modified their
compilers to reverse the loop indices.
In any event, even with the reversed loop indices, this code causes
the reading of three more arrays per time step, which needs to be included
in the total tally of memory traffic.
Summary
|
102.swim
|
171.swim |
| MAIN |
negligible |
3 arrays Read (assumes
advanced compiler optimizations) |
| CALC1 |
3 arrays Read
4 arrays Written
4 arrays Allocated |
3 arrays Read
4 arrays Written
4 arrays Allocated |
| CALC2 |
7 arrays Read
3 arrays Written
3 arrays Allocated |
7 arrays Read
3 arrays Written
3 arrays Allocated |
| CALC3 |
9 arrays Read
6 arrays Written
0 arrays Allocated |
9 arrays Read
6 arrays Written
0 arrays Allocated |
| Sum |
19 arrays Read
13 arrays Written
7 arrays Allocated |
22 arrays Read
13 arrays Written
7 arrays Allocated |
| Time Steps |
1710 |
800 |
| Total Traffic |
53.64 GB (w/o allocates)
65.38 GB (w/ allocates) |
371.8 GB (w/o allocates)
446.1 GB (w/ allocates) |
Correlation Between SWIM-Estimated Results and STREAM Results
I have done various "spot-checks" over the years showing that there is
a reasonable correlation between these SWIM-based estimates and directly
measured STREAM results, but there is also a fair degree of "fuzz" due
to the various assumptions involved (relating to compilers, cache replacement
policy, and page coloring issues).
Here is a set of results illustrating the magnitude of the "fuzz" in
this performance projection for systems with published SPEC and STREAM
data. This chart is based on all of the SPECfp_rate2000 data published
as of November 13, 2002, combined with all of the published STREAM data
for identical systems. This amounted to 48 results, representing
something like 10 rather different system architectures (depending on how
you define "rather different").
For the purposes of the following graph, it is assumed that the "SWIM
BW" is equal to 446.1 GB per run of the SPEC 171.swim benchmark.
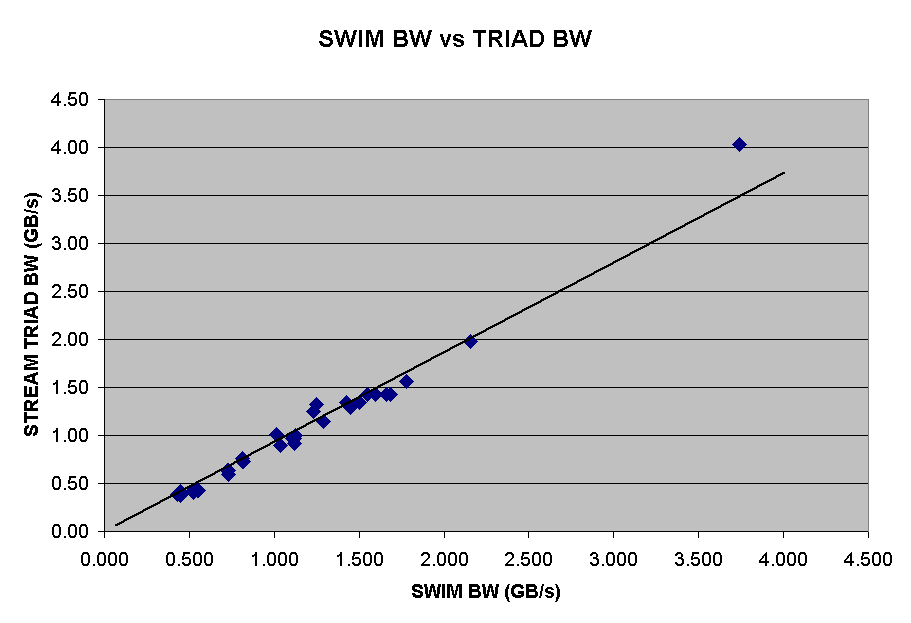
It is easy to see that the correlation is excellent, with a "best-fit"
linear trend having a slope very close to unity. For
those who enjoy statistics, the R-squared value of the fit is 0.967 and
the standard error is 0.11, relative to a mean value of 0.89 GB/s (per
cpu). The coefficient of the best-fit linear curve (assuming
zero intercept) is 1.06 +/- 0.03. Given the rather large number
of assumptions in this approach, a 6% systematic error seems quite acceptable
for a rough estimate of the system's sustainable memory bandwidth.
The magnitude of the systematic error is minimized if I assume that
171.swim moves 420 GB per copy instead of the 446.1 GB per copy. This
number is easy to remember and results in a best-fit slope within 1%
of unity. (The statistics do not otherwise change --- the R-squared
value is still 0.967.) Note that using 420 GB per copy is only
intended to give estimates for STREAM Triad on systems that are
similar to the systems with published results. It glosses over
the issue of whether all the machines are using a write-allocate policy
on all of the store misses in STREAM and 171.swim, and therefore
does not attempt to show all of the memory traffic on a
system -- just the part that corresponds to STREAM Triad performance.
An Alternate Scheme when Similar Results are Available
When STREAM benchmark results are available for a system that is very similar
to the system that you are curious about, the ratio of the 171.swim results
is
sometimes useful as a scaling factor for the known STREAM results.
You have to understand the relevant parts of the system architecture and
control for the
software carefully, however.
Here are two examples:
HP AlphaServer ES45/1000 and ES45/1250
STREAM benchmark results are available for the HP AlphaServer ES45/1000,
but not (yet) for the ES45/1250. SPECfp_rate2000 performance
results
are available on both systems. The following table shows the
relevant values and ratios.
| |
STREAM Triad
|
171.swim time
|
Estimated "SWIM BW"
|
Ratio
|
|
ES45/1000 1p
|
1.978 GB/s
|
206 seconds
|
2.039 GB/s
|
1.0308
|
|
ES45/1000 2p
|
2.850 GB/s
|
264 seconds
|
3.182 GB/s
|
1.1649
|
|
ES45/1000 4p
|
3.583 GB/s
|
431 seconds
|
3.898 GB/s
|
1.0879
|
This table shows that the ratio of STREAM to 171.swim performance
fluctuates somewhat, but that the actual system delivers slightly less
STREAM Triad bandwidth than the "best-fit" value of 420 GB per copy
would suggest.
To use the ES45/1000 data as a basis for estimating ES45/1250
performance, it is important to understand exactly what is different
between the two systems. A review of the specifications (at various
spots on www.hp.com) shows that the bus speeds are the same for the
two systems, and that the cache on the ES45/1250 is 16 MB per cpu,
compared to 8 MB/cpu on the ES45/1000. SPECfp_rate2000
results are available on both systems, with the ES45/1000 results
above, and the ES45/1250 requiring 404 seconds to run four copies of
171.swim. If I used the formula above for the
ES45/1000, I would estimate the 4-way STREAM Triad value to be (4 copies
* 420 GB/copy / 431 seconds) = 3.898 GB/s, while the published value
is 3.583 GB/s. Rather than using the 420 GB estimate for
the memory traffic, it makes sense in this case to simply scale the
3.583 GB/s observed on the ES45/1000 by 431 seconds/404 seconds to
give an estimate of 3.822 GB/s for the ES45/1250. Again,
this is not a STREAM number, but given the similarity of the hardware
and software, this estimate is probably a bit closer to the actual value
than I would have gotten by assuming the average value of 420 GB per copy.
HP rx2600 & rx5670
STREAM benchmark results are available for the HP rx2600, a dual-cpu
system using the Intel Itanium2 processor. Only single-cpu
STREAM results are
available for this system, though SPECfp_rate2000 results are available
for 1 processor and 2 processors, and are available for 1, 2, and 4 processors
on the
very similar rx5670 system. The rx2600 delivers a STREAM Triad
result of 4.028 GB/s, while the estimate based on the SWIM performance
is 3.529 GB/s.
So for some reason, this system does a bit better on STREAM than the
average of the systems used in the "best fit" above. Using
the 4.028 GB/s as a
baseline, I can use the ratios of the 171.swim performance to obtain
estimates of STREAM Triad performance that are probably somewhat more
accurate
than those obtained by the average value of 420 GB per copy.
For the rx2600, the known 1p STREAM value is 4.028 GB/s.
The 1p and 2p 171.swim times are 119 seconds and 223 seconds, leading to
a 2p STREAM
Triad estimate of 4.028 GB/s * 2 copies * 119 seconds / 223
seconds = 4.299 GB/s.
For the rx5670, the 171.swim times are 111, 195, and 397 seconds for
1, 2, and 4 copies, respectively. These lead to STREAM Triad
estimates of
4.028 GB/s * (119 seconds / 111 seconds) = 4.318 GB/s for a single
processor, 4.028 GB/s * 2 copies * (119 seconds / 195 seconds) =
4.916 GB/s
for two processors, and 4.028 GB/s * 4 copies * (119 seconds
/ 397 seconds) = 4.830 GB/s for four processors.
Note the very slight degradation
in throughput when running four copies of the 171.swim benchmark on
a single shared bus.
Summary
For systems with the most common cache architectures and cache sizes, analysis
of the SWIM codes from SPEC CPU95 and SPEC CPU2000 provides a methodology
for estimating sustainable memory bandwidth. For the
set of 48 results where direct comparisons are possible, assuming that
the SWIM benchmark moves 446.1 GB of data across the main memory interface,
this methodology gives estimates of STREAM TRIAD performance with a systematic
error of 6%, and a standard error relative to the best fit of approximately
12%. Since STREAM itself was never meant to be more than
a guide to sustainable memory bandwidth, this level of accuracy is quite
acceptable for coarse characterization of the sustainable memory bandwidth
of current systems.
When STREAM benchmark results are available on a very similar system,
using the ratio of 171.swim throughput to scale the known STREAM Triad
results can provide another useful method for estimating sustainable
memory bandwidth.