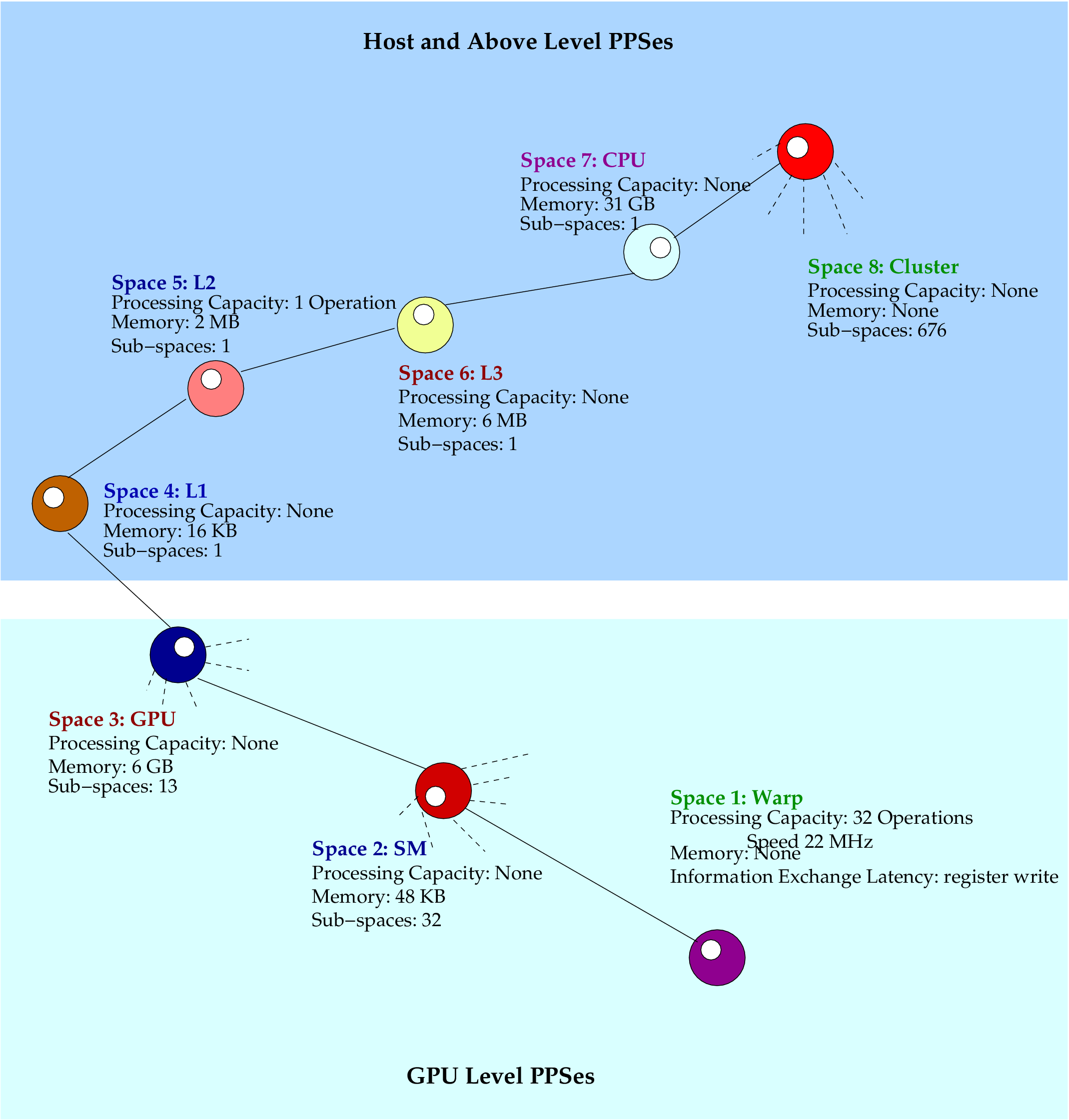
We have used the gpu queue in the Big Red II supercomputer of Indiana University as the back-end for the hybrid compiler. Each node in the queue has a 16-core AMD Opteron 6276 server processor (the same CPU used in the Hermes machines) and an NVIDIA K20 GK110 GPU. Host CPU memory per node is 31 GB and the GPU has a 6 GB card memory. A K20 GPU has 13 symmetric multiprocessors (SMs) as apposed 14 of the K20X GPU. The remaining configurations are the same in both GPUs. All three IT programs we have run on the queue are single-task programs mapped to the GPU model of the machine. The PCubeS description of the queue for the GPU model is illustrated in below figure.
We have used a maximum of 8 nodes to run the programs due to availability restrictions. Big Red II is a Cray machine that provides an integrated Cray environment for compiling and running programs. At the time of the experiments, the environment had PrgEnv-cray/5.2.82 set as the default. The underlying C++ compiler was crayc++ and the MPI implementation was cray-mpich/7.3.2. The CUDA compiler was nvcc 7.0, V7.0.27. As in the previous two platforms, back-end compilers had O3 optimization flag turned on. In addition, CUDA codes have been compiled with compute architecture setting 3.5 (arch=sm_35 parameter).