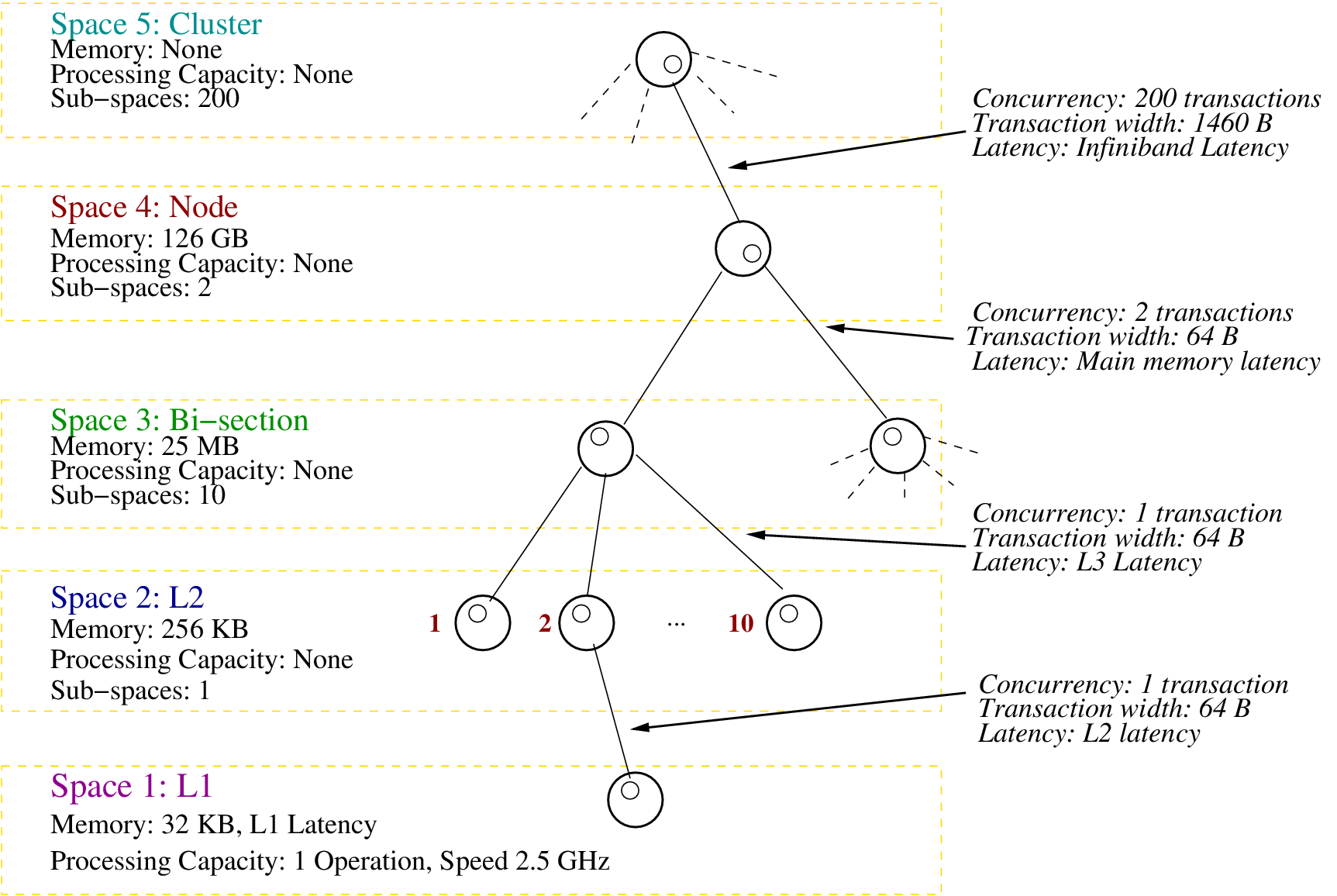
We have used the parallel partition in the Rivanna compute cluster of ARCS, UVA as the back-end for segmented memory compiler. The parallel partition has two 2.50 GHz Intel Xeon E5-2670 CPUs in each compute node. These nodes are connected by an Infiniband interconnect. Each CPU has 10 cores and three cache levels. A 25 MB L3 cache segment is shared among 10 cores. Then each core individually has a 256 KB L2 and a 32 KB L1 cache. Memory per node is 126 GB. The PCubeS description of the parallel partition is shown in below figure.
Although the parallel partition has many more nodes, due to our allocation restriction, we have limited the nodes count to 50 in the experiments. Thus the maximum number of cores being used in the experiments is 1000. The native MPI compiler in this platform is mpic++ that uses Intel’s icpc version 14.0.2 C++ compiler underneath and the Open MPI Intel implementation (openmpi/intel/1.8.4) for message passing. Finally, note that Intel Xeon E5-2670 supports vector instructions but automatic vectorization through the underlying icpc compiler was working for neither IT executables nor reference implementations. Therefore, we ignore that capacity.