This page does not represent the most current semester of this course; it is present merely as an archive.
The perf labs are working labs; there is not separate lab and homework assignments.
The associated homeworks are both the same file and are submitted as the same submission entry. However, they have distinct due dates. I’ll take a snapshot of the submissions at rotate’s due date and use it to compute rotate’s score.
You may work with a single partner for both smooth and rotate, or may work alone.
Q: Can I switch partners between rotate and smooth?
A: It can be done, but you’ll need to talk to Prof Tychonievich so he can fix the grading script to handle your swap.Q: Can I have a partner for rotate and then work solo for smooth?
A: YesQ: Can I work solo for rotate and then have a partner for smooth?
A: It can be done, but you’ll need to talk to Prof Tychonievich so he can fix the grading script to handle your joining up.Q: Can we work in a group of three?
A: NoQ: Can my partner and I be from different lab sections?
A: Yes, if you can both attend the same lab section for this assignment.
The following kinds of conversations are permitted with people other than your partner or course staff:
drawings and descriptions of how you want to handle memory accesses across an image
code snippets explaining optimizations, but only for code unlike the smooth and rotate problems we are discussing
discussion of the code we provide you: how RIDX works, what the naive implementations are doing, etc.
Download perflab-handout.tar on linux.
run tar xvf perflab-handout.tar to extract the tarball, creating the directory perflab_handout.
Edit kernels.c; on lines 12 through 20 you’ll see a team_t structure, which you should initialize with your name and email (and your partner’s, if you have one), as well as what you’d like your team to be called in the scoreboard.
kernels.c is the only file you’ll get to submit, though you are welcome to look at the others or even modify them for debugging purposes.
This assignment deals with optimizing memory-intensive code. Image processing offers many examples of functions that can benefit from optimization. In this lab, we will consider two image processing operations: rotate, which rotates an image counter-clockwise by 90◦, and smooth, which smooths
or blurs
an image.
For this lab, we will consider an image to be represented as a two-dimensional matrix M, where Mi,j denotes the value of (i, j)th pixel of M. Pixel values are triples of red, green, and blue (RGB) values. We will only consider square images. Let N denote the number of rows (or columns) of an image. Rows and columns are numbered, in C-style, from 0 to N − 1.
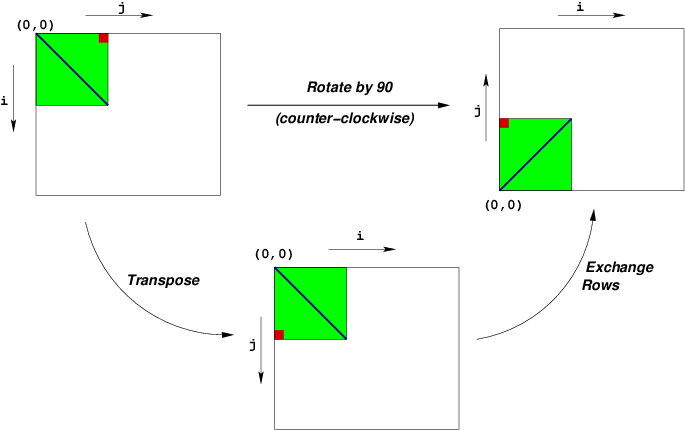
Given this representation, the rotate operation can be implemented quite simply as the combination of the following two matrix operations:
This combination is illustrated in the following figure:
Smooth is designed to benefit from different optimizations than rotate
The smooth operation is implemented by replacing every pixel value with the average of all the pixels around it (in a maximum of 3 × 3 window centered at that pixel).
Consider the following image:
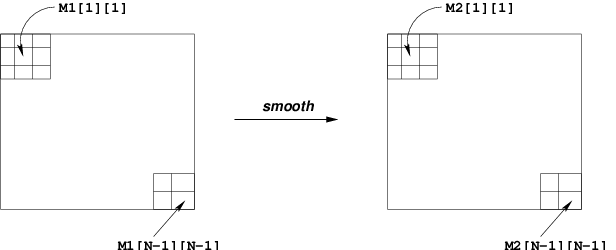
In that image, the values of pixels M2[1][1] is
| |||||||
| 9 |
In that image, the value of M2[N-1][N-1] is
| |||||||
| 4 |
A pixel is defined in defs.h as
typedef struct {
unsigned short red;
unsigned short green;
unsigned short blue;
} pixel;Images are provided in flattened arrays and can be accessed by RIDX, defined as
#define RIDX(i,j,n) ((i)*(n)+(j))by the code nameOfImage[RIDX(index1, index2, dimensionOfImage)].
All images will be square and have a size that is a multiple of 32.
In kernel.c you will see several rotate and several smooth functions.
naive_rotate and naive_smooth should not be changed. We will compare your code to the original naive code; if you change the naive code you won’t be able to tell how well you are doing.
You may add as many other rotate and smooth methods as you want. You should put each new optimization idea in its own method: rotate_outer_loop_unrolled_3_times, smooth_with_2_by_3_blocking, etc. The driver will compare all your versions as long as you register them in the register_rotate_functions or register_smooth_functions methods.
The source code you will write will be linked with object code that we supply into a driver binary. To create this binary, you will need to execute the command
unix> make driverYou will need to re-make driver each time you change the code in kernels.c. To test your implementations, you can then run the command:
unix> ./driverThe driver can be run in four different modes:
If run without any arguments, driver will run all of your versions (default mode). Other modes and options can be specified by command-line arguments to driver, as listed below:
-g: Display only the fastest functions (autograder mode).-f <funcfile> Execute only those versions specified in <funcfile> (file mode).-d <dumpfile>: Dump the names of all versions to a dump file called <dumpfile>, one line to a version (dump mode).-q: Quit after dumping version names to a dump file. To be used in tandem with -d. For example, to quit immediately after printing the dump file, type ./driver -qd dumpfile.-h: Print the command line usage.Violations of the following rules will be seen as cheating, subject to penalties that extend beyond the scope of this assignment:
Additionally, the following rules will result in grade penalties within this assignment if violated:
Speedups vary wildly by the host hardware. I have scaled the grade based on my timing server’s hardware so that particular strategies will get 75% and 100% scores.
Smooth and Rotate will each be weighted as a full homework assignment in gradebook.
Rotate will get 0 points for 1.0× speedups on my computer, 75% for 1.3×, and 100% for 1.6× speedups, as expressed in the following pseudocode:
if (speedup < 1.0) return MAX_SCORE * 0;
if (speedup < 1.3) return MAX_SCORE * 0.75 * (speedup - 1.0) / (1.3 - 1.0);
if (speedup < 1.6) return MAX_SCORE * (0.75 + 0.25 * (speedup - 1.3) / (1.6 - 1.3));
return MAX_SCORE;Smooth will get 0 points for 1.0× speedups on my computer, 75% for 1.2×, and 100% for 2.0× speedups, as expressed in the following pseudocode:
if (speedup < 1.0) return MAX_SCORE * 0;
if (speedup < 1.2) return MAX_SCORE * 0.75 * (speedup - 1.0) / (1.2 - 1.0);
if (speedup < 2.0) return MAX_SCORE * (0.75 + 0.25 * (speedup - 1.2) / (2.0 - 1.2));
return MAX_SCORE;Exact speedups may vary by computer; see the submission results page for what speedup I found from your most recent submission. Experience has shown that timing does not change by more than .03× upon resubmission.
You will submit only kernels.c, and need submit it only once per homework though you probably want to submit it often to see what my server’s timing results are.
Submit at the usual place. One of my machines will attempt to time your code and post the speedups I find here. Since running all of the timing for everyone’s code can take a while, expect 30-60 minute delays before your results are posted. I time all of your code and report only the fastest run of each method, so it is in your interest to have several optimizations in your submission; note, however, that if your code runs for more than 5 minutes I will stop running it and post no results.
If you are in a team, it does not matter to me if one or both partners submit so long as at least one does.