
What can we store about family history research?
During RootsTech’s Innovator Summit I presented a talk entitled
I could write at length about picking talk titles.
For now, let me just point out this template,
very common in talks that actually get billing:
something catchy, witty, or provocative;
then a colon;
and then something serious, descriptive, or dull.
“From Purple Prose to Machine-Checkable Proofs: Levels or Rigor in Family History Tools.”
At the time of writing, you can watch it on rootstech.org
but since I have no idea how long that link will be live
and since this is a blog not a vlog
If “web log” turns into “blog”,
shouldn’t “video log” turn into “olog”?
,
I’ll summarize some of that talk in this post
and then describe some related ideas from others.
My slides are also available.
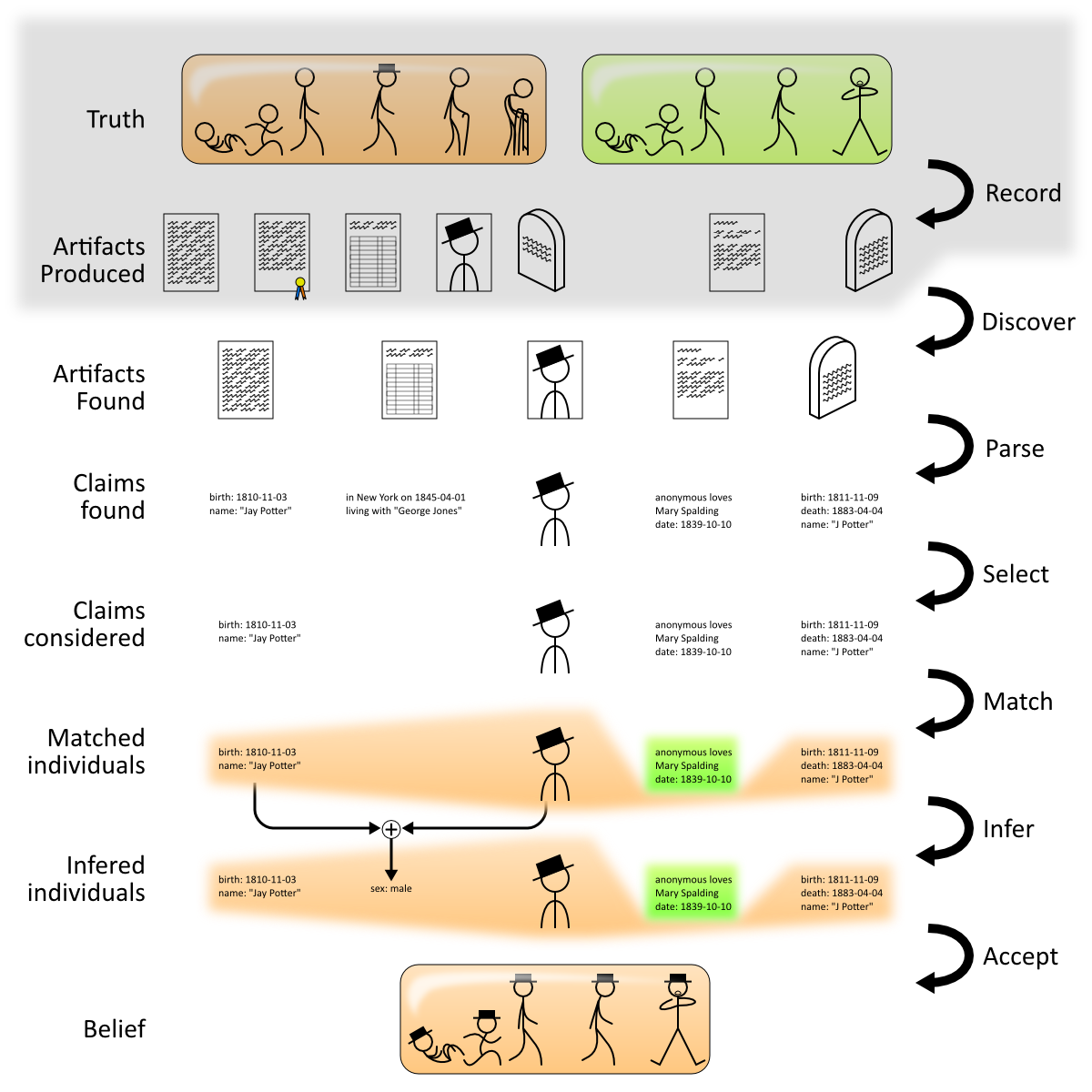
My basic thesis was that there is a difference between rigorous research and rigorous recording of research. I compared this to proving code is correct compared to storing proof-carrying code: the former is hard, but the latter (though uncommon) is completely solvable. I then broke down research (based mostly on this image) and talked about the idea of carrying the rigor and how much work is needed to get to that point. Since it was my talk, I talked about the kinds of ideas I find compelling, which means an unusually strong emphasis on inferences. But I didn’t fully conform the talk to Polygenea or the like; I mentioned ideas I personally feel don’t go far enough if they were the most direct means reach the part of the rigorous storage I was discussing, and so on.
I’m not the only one to think about these topics, nor have my ideas been the only way to approach them. Scott Woodfield shared with me a pre-print draft of a paper entitled “A Superstructure for Models of Quality” which he is writing/has written I’m actually not sure whether it is in progress or not; he gave me an incomplete draft, but there is a more complete version here. with David Embly and Stephen Liddle describing a modeling framework aligned with the seven levels of abstraction described in Charles Meadow’s 1992 book Text Information Retrieval Systems. I’ve never read this book and know little about it. Their approach is to describe a date model that aligns with levels of abstraction generally, and then map those levels to the various parts of Family History. I have not spent the effort to internalize all of what their work would imply if applied to an actual tool, but I found it intriguing and worthy of additional investigation.
There was also a panel session on a similar topic, but it was scheduled at the same time as a meeting of the Early Mormon Research Group so I was not able to attend. However, I did have a chance to visit with one of the panellists, Robert Anderson of the Great Migration project and member of the working group that created the GenTech Data Model. We talked about the the research process and date generally, mostly ideas that are also found in his new book Elements of Genealogical Analysis. He was kind enough to give me a copy, which I read with interest. Most of its contents lined up with what I already know, but presented clearly. It was interesting, though, to read from the perspective of someone who is working in a space where there has been previous research and how that finding and interpreting the work of others figures into his process. However, the most interesting part of all to me, though just a small side point, was his use of the phrase “external information” to mean all of the antecedents of inference that are not claims made by any particular artefact.
It is not clear to me that any of these three kinds of approaches is the right one, but it is heartening to see the similarity between them. Rigorous research is hard and perfect research almost certainly unattainable, but the structure of rigorous research appears to be describable and to admit machine understandable recording.
More RootsTech and Family Search Develop Conference reports will follow in my next post.
{kind=link}
Looking for comments…