
One major bottleneck in the code is the solution of a linear, constant-coefficient elliptic equation to recover the streamfunction from the new vorticity field at each time step. This equation is solved by Fourier transformation along the second index of the array (vectorizing over the first index), followed by solution of the resulting independent tridiagonal matrices. This second step has a data dependency on the first array index. On Cray machines, the compiler automatically vectorizes on the second index (using non-unit strides). On hierarchical-memory machines, it is generally more efficient to keep the data dependence in the inner loop and use unit strides, though for small array sizes (or very deep pipelines) it is preferable to place the second index innermost and suffer the resulting increase in cache misses.
The QG_GYRE benchmark code has been in existence for several years, and has undergone several revisions. The results here are from all three versions of the code (QGBOX, QGBENCH, and QG_GYRE), but they have been editted to remove cases where extensive "tweaking" was performed or where the run size was too small relative to the machine's cache.
Figure 1. Ratio of several performance indicators to the performance of the QG_GYRE code. In each computer family, the fastest machines are listed to the left.
The machines are
From these results, it is clear that the ratio of QG_GYRE to STREAM Triad provides the least variability, both within and across processor families.
It is, of course, an abuse of the SPECfp92 metric to try to correlate this aggregate measure with performance on one particular application code. Some preliminary work to compare the QG_GYRE performance with the individual SPECfp92 tests has shown no good correlations across processor families (though good correlatations within several processor families were found).
The recommended procedure of determining which of the individual SPECfp92 tests correlates best with one's code is a non-trivial matter, for several reasons:
Application Performance ------------------------ Stream Triad Performancegives information about such factors as data re-use or extra data movement. Ratios greater than one will generally indicate a degreee of data re-use, while ratios less than one indicate that the application's performance is limited by cpu or other resources.
For the machines that we have been looking at, the ratios are:
Cray C90 0.50
Y/MP 0.58
J916 0.86
EL/98 1.09
HP 9000/755 2.21
/730 2.63
/720 2.80
IBM RS/6000-990 1.31
-580 1.55
-550 1.31
-320 1.72
-250 2.00
SGI Power Challenge 2.83
Challenge 2.83
Indigo/R4000 2.36
DEC 4000/710 2.74
3000/500 2.46
The ratio appears to have some correlation with cache size, with the SGI Power Challenge, the SGI Challenge, and the DEC 4000/710 having multi-MB cache sizes and large ratios. The Cray EL/98 has an increased ratio because it has more floating-point pipelines per memory port than the other Cray machines.
Within each processor family, the ratio is almost constant (as noted above), and the constant is only weakly dependent on the family, with values very close to 2.5 for DEC, HP, and SGI, 1.5 for IBM, and 0.5-0.9 for the Cray machines. Because the high ratios are in part due to data re-use, they are a function of problem size, as will be investigated in the next section.
We define efficiency as the fraction of Peak MFLOPS obtained when running the QG_GYRE benchmark. Results for the Cray C90, SGI Power Challenge, and IBM RS/6000-990 are shown in Figure 2.
Author's Note: I plan to replace the Cray C90 results with Cray J90 results in the final version, since this would make the three machines listed comparable in price/cpu. Based on my preliminary results, the J90 and C90 curves will be quantitatively very similar.
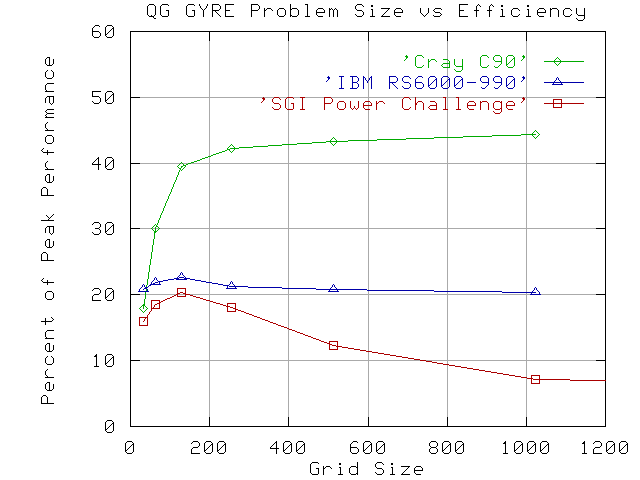
Figure 2. Fraction of Peak performance obtained on the QG_GYRE benchmark as a function of problem size on three computers.
Comments: