CS 6501: Text Mining Spring 2019 · CS@UVa
This assignment is designed to help you get familiar with supervised Hidden Markov Model for Port-of-speech Tagging. It consists of three parts, totaling 100 points. The implementation could be largely based on what you have developed for MP1.
- Part 1: Parameter Estimation (20 points): using the maximum likelihood estimator to estimate the model parameters in an Hidden Markov Model (HMM);
- Part 2: Tag Sequence Inference (50 points): implementing the Viterbi algorithm to perform the maximum a posterior inference and retrieve the best tag sequence for a given input text sentence.
- Part 3: Generate Sentence via an HMM (30 points): synthesizing natural language sentences from an HMM via sampling.
The deadline and submission guidance are explicitly described here.
Data Set
The instructor has prepared a small collection of Penn Treebank tagged documents for Part of Speech (in total 199 tagged documents). The data set can be downloaded here.
Originally, each of the texts was run through PARTS (Ken Church's stochastic part-of-speech tagger) and then corrected by a human annotator. The square brackets surrounding phrases in the texts are the output of a stochastic NP parser that is part of PARTS and are best ignored. Words are separated from their part-of-speech tag by a forward slash. In cases of uncertainty concerning the proper part-of-speech tag, words are given alternate tags, which are separated from one another by a vertical bar.
The definition of tags can be found here.
Note: as in Penn Treebank the definition of tags is changing over time, you might find some tags that are not defined in the latest Penn Treebank list. And since this is only a small subset of Penn Treebank annotated corpus, many tags might not occur in this data set. Therefore, you only need to consider the tags occurred in this provided data set.
Sample implementation
Please reuse your implementation in MP1 for loading files from a directory, parsing text input (removing unnecessary annotations from this data set), and using hashmap for language models to finish this assignment.
Preparation: Hidden Markov Model
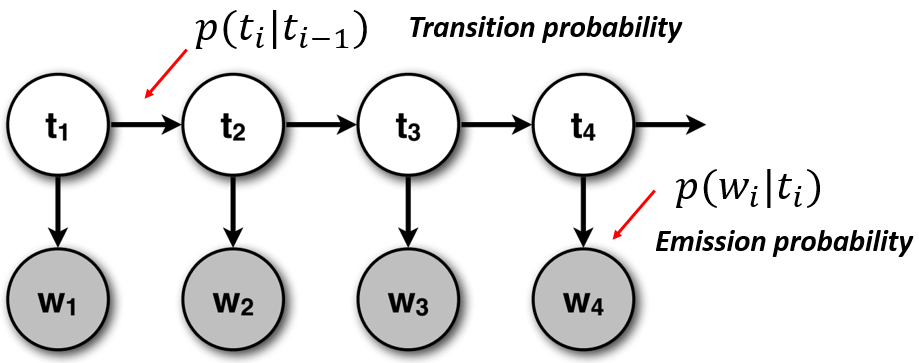
Figure 1. Graphical representation of Hidden Markov Model
A Hidden Markov model captures the joint probability between a word sequence and the corresponding tag sequence, i.e., $p(w_1,\dots,w_n,t_1,\dots,t_n)$, by making the following two independence assumptions:
1. Current tag $t_i$ only depends on previous $k$ tags:
$$p(t_1,\dots,t_n)=\prod^n_{i=1} p(t_i|t_{i-1},\dots,t_{i-k})$$
2. Each word in the sequence depends only on its corresponding tag:
$$p(w_1,\dots,w_n|t_1,\dots,t_n)=\prod^n_{i=1} p(w_i|t_{i})$$
In particular, $p(t_i|t_{i-1},\dots,t_{i-k})$ specifies the transition probability among consecutive tags, and $ p(w_i|t_{i})$ specifies the emission probability from a tag to a word. In this assignment, we will only use the first-order HMM, i.e., current tag only depends on the previous one tag ($k=1$). And to make the implementation unified, we will add a dummy tag START at the beginning of each sentence: it does not generate any word, it can only transit to other tags, and no tag can transit to this tag.
Part1: Parameter Estimation (20pts)
We will use the Maximum Likelihood Estimator (MLE) for parameter estimation in HMM. Specifically, the transition and emission probabilities can be estimated as follows,
$$p(t_i|t_j)\propto c(t_j,t_i)+\delta, ~~~~~~~~ p(w_i|t_j)\propto c(w_i,t_j)+\sigma$$
where $c(t_j,t_i)$ denote the count that tag $t_i$ follows $t_j$ in the training corpus, $c(w_i,t_j)$ denotes the count that word $w_i$ is assigned to tag $t_j$, $\delta$ and $\sigma$ are the smoothing parameters for transition and emission probabilities estimation. In this assignment, we set $\delta=0.5$ and $\sigma=0.1$.
Hint: you should use your previous language model implementations to realize these two probabilities. For example, for each pos tag $t$ create one unigram language model over the vocabulary for emission probability and one unigram language model over the whole tag set for transition probability.
What to submit:
- Paste your implementation of maximum likelihood estimation for HMM. (15pts)
- List the top 10 most probable words under the tag "NN" and top 10 most probable tags after the tag "VB". (5pts)
Part2: Viterbi Algorithm for Posterior Inference (50pts)
The posterior inference in HMM, $argmax_{t_1,\dots,t_n} p(w_1,\dots,w_n|t_1,\dots,t_n)p(t_1,\dots,t_n)$ can be efficiently performed via the Viterbi algorithm, which essentially is dynamic programming. To implement this algorithm, you need to create a special data structure called Trellis, which stores the best tag sequence for $w_1,w_2\dots,w_i$ that ends with tag $t_j$ in its cell $T[j][i]$. Detailed description of this algorithm can be found in our lecture slides.
The output of Viterbi algorithm is the best tag sequence $t_1,\dots,t_n$ for the input word sequence $w_1,\dots,w_n$. Please note the Trellis structure should be created for each input sentence, as different sentences might have different length.
What to submit:
- Paste your implementation of the Viterbi algorithm for HMM. (20pts)
- Perform 5-fold cross-validation on the provided Penn Treebank annotation set, use tag prediction accuracy/precision/recall on test set as your evaluation metric. Report overall accuracy/precision/recall over all tags, and the precision/recall for the tags of "NN", "VB", "JJ", and "NNP". (15pts)
- Tune the smoothing parameter of $\delta$ and $\sigma$ and repeat your cross-validation, figure out the best configuration for $\delta$ and $\sigma$ on this data set. (15pts)
Generate Sentence via an HMM (30pts)
As an HMM specifies the joint distribution between words and tags in a generative way, i.e., $p(w_1,\dots,w_n,t_1,\dots,t_n)=\prod^n_{i=1}p(t_i|t_{i-1})p(w_i|t_{i})$ in a first-order HMM, we can synthesize natural language sentences by sampling from an HMM.
The same sampling procedure that you have implemented in MP1-Part2 can be applied here. We will sample with respect to a specific order: first sample the current tag based on previous tag from transition probability, and then same the current word from current tag from corresponding emission probability. We will start from the dummy tag START for each sentence, and fix the sentence length to 10.
Record both the sampled tag sequence and word sequence for each sentence, and corresponding log-likelihood of $p(w_1,\dots,w_n,t_1,\dots,t_n)$ computed by HMM.
We will use the HMM estimated from the whole corpus on the provided Penn Treebank annotation set, and use the best $\delta$ and $\sigma$ you have found in the previous question.
What to submit:
- Paste your implementation of the sampling procedure in an HMM. (10pts)
- Generate 100 sentences by sampling from the trained HMM, and list the top 10 sentences of the highest log-likelihood. Do you feel we have generated more natural/readable sentences than those we had in MP1-Part2? (10pts)
- Use your sampled 100 sentences as testing instances of your trained HMM (i.e., run your Viterbi algorithm on those sentences). Evaluate accuracy of the inferred tags against your generated tags in each sentence, and report the average tagging accuracy over all these sentences. Can you find any correlation between this sentence-level tagging accuracy and the log-likelihood of each sentence? Why would we expect such a pattern? (10pts)
Deadlines & How to submit
You will have 14 days on this assignment, i.e., the due date is March 16th, 11:59pm. A collab assignment page have been created for this MP. Please submit your written report strictly following the requirement specified above. The report must be in PDF format, and simply name your submission by your computing ID dash MP2, e.g., "hw5x-MP2.PDF".
Reference solution
We have prepared the following sample solution for your reference, and hopefully it helps answer some of your confusions or questions about MP2. Sample Solution