 Department
of Computer Science
Department
of Computer Science
School of Engineering and Applied Science
University of Virginia,
Charlottesville,
Virginia
FAQ's
What is STREAM?
The STREAM benchmark is a simple synthetic benchmark program that measures
sustainable memory bandwidth (in MB/s) and the corresponding computation
rate for simple vector kernels.
Why should I care?
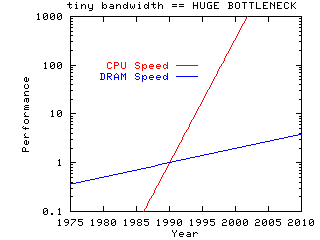
Computer cpus are getting faster much more quickly than computer memory
systems. As this progresses, more and more programs will be limited in
performance by the memory bandwidth of the system, rather than by the computational
performance of the cpu.
As an extreme example, several current high-end machines run simple
arithmetic kernels for out-of-cache operands at 4-5% of their rated peak
speeds --- that means that they are spending 95-96% of their time idle
and waiting for cache misses to be satisfied.
The STREAM benchmark is specifically designed to work with datasets
much larger than the available cache on any given system, so that the results
are (presumably) more indicative of the performance of very large, vector
style applications.
If you want more words, I have written a paper on STREAM:
Sustainable
Memory Bandwidth in Current High Performance Computers
A somewhat broader look on the issue, see my paper: Memory
Bandwidth and Machine Balance in Current High Performance Computers.
STREAM is also a useful component of models for scaling of homogeneous throughput workloads
(like the SPEC CPU "rate" benchmarks). Examples of models based on STREAM measurements that
do a pretty good job of estimating SPECfp_rate2000 scaling are included in several
presentations.
Getting Started
STREAM is relatively easy to run, though there are bazillions of variations
in operating systems and hardware, so it is hard for any set of instructions to be comprehensive.
It is strongly recommended that you compile the STREAM benchmark
from the source code (either Fortran or C).
If it is not possible to compile the code yourself there are a few
obsolete precompiled binaries that might work. Most of these are very old
and even if they run they are unlikely to give good performance (because they
use old instruction sets) and are unlikely to obey the current STREAM
run rules
(because the arrays are too small given the cache sizes on current processors).
If there is not a precompiled binary, then you have to compile the code.
Run Rules
The run rules for a compliant "standard" STREAM benchmark run are contained
here and in comments in the source code.
- You are free to use this program and/or to redistribute this program.
- You are free to modify this program for your own use, including commercial use,
subject to the publication restrictions in item 3.
- You are free to publish results obtained from running this program, or from
works that you derive from this program, with the following limitations:
- In order to be referred to as "STREAM benchmark results",
published results must be in conformance to the STREAM
Run Rules, (briefly reviewed below) published at
STREAM FAQ
and incorporated herein by reference.
- As the copyright holder, John McCalpin retains the
right to determine conformity with the Run Rules.
- Results based on modified source code or on runs not in accordance
with the STREAM Run Rules must be clearly labelled whenever they
are published. Examples of proper labelling include:
- "tuned STREAM benchmark results"
- "based on a variant of the STREAM benchmark code"
Other comparable, clear, and reasonable labelling is acceptable.
- Submission of results to the STREAM benchmark web site is encouraged, but not required.
- Use of this program or creation of derived works based on this
program constitutes acceptance of these licensing restrictions.
- Absolutely no warranty is expressed or implied.
Uniprocessor Runs
If you want to run STREAM on a single processor, then you are in luck --
it is an easy thing to do. Grab the source code from the source
code directory. You will need the main STREAM
code in either Fortran or C, and you will need a timer code. For
Unix/Linux systems, the timer code included in the C version (and also provided
separately in the file "mysecond.c" works fine.
Some systems provide higher resolution timers -- check with the documentation
on your own unix/linux box to see what you have access to.....
Please note that I generally reject new measurements based on "cpu timers"
(even for uniprocessor runs) because of both poor resolution and systematic
inaccuracies in the this function on many/most systems. Wall clock timers are
much more reliable.
There are a number of versions of the STREAM code code in both FORTRAN and C.
The most recent versions are named "stream.f" and "stream.c" (shocking!).
(I use STREAM in uppercase as the name of the benchmark, but I prefer not
to use uppercase for file names that I have to type often, so I have left
those in lowercase.)
Simple Compilation Instructions
First you need to get either the
C code
or the
FORTRAN code
plus the
external timer code.
On most Linux systems, you can compile a standard-conforming
(single cpu) version of STREAM with the simple command:
gcc -O stream.c -o stream
Please let me know if this does not work!
In FORTRAN, the corresponding compilation is either:
gcc -c mysecond.c
g77 -O stream.f mysecond.o -o stream
or sometimes
gcc -c -DUNDERSCORE mysecond.c
g77 -O stream.f mysecond.o -o stream
Please let me know if either of these does not work!
A note about optimization of results:
The STREAM run rules allow some flexibility in the
runs (as discussed in the Detailed Run Rules below).
The arrays are required to be much larger than the largest
cache(s) used, but the offset between the arrays can be
set to any (non-negative) value. The default array size
is 2 million elements (which is large enough to satisfy the
run rules for systems with caches of up to 4 MB -- i.e., most
current computer systems), and the default offset is 0 elements.
Many people have obtained improved results by fiddling
with the offset variable (OFFSET -- defined at line 59 of
"stream.c"). It is very hard to give guidance here
because every computer family has slightly different details
for memory conflicts --- experimentation is a much easier
way to get good results than detailed understanding!
Multiprocessor Runs
If you want to run STREAM on multiple processors, then the situation is
not quite so easy.
First, you need to figure out how to run the code in parallel.
There are several choices here: OpenMP, pthreads, and MPI.
-
OpenMP:
The standard STREAM codes in FORTRAN and C now include OpenMP
directives. So if you have a compiler that supports OpenMP,
all you have to do is figure out what flag(s) are used to enable OpenMP
compilation and what environment variables are needed to control the
number of processors/threads used.
-
Some of the newest versions of gcc support OpenMP:
gcc -fopenmp -D_OPENMP stream.c -o stream
export OMP_NUM_THREADS=2
./stream
Check the output to see if the following line appears:
Number of Threads requested = 2
-
On POWER or PowerPC systems running
the IBM compilers, the process would look like:
xlc -qsmp=omp -O stream.c -o stream
export OMP_NUM_THREADS=4
./stream
or in FORTRAN
xlc -qsmp=omp -c mysecond.c
xlf_r -qsmp=omp -O stream.f mysecond.o -o stream
export OMP_NUM_THREADS=4
./stream
Unfortunately, command line options differ on essentially all compilers.
RTFM.
-
MPI:
If you want multi-processor results, but you have a cluster
or do not have an OpenMP compiler, you might consider the
MPI version of STREAM ("stream_mpi.f", in the "Versions"
subdirectory). This will require that you have MPI support
installed (something like MPICH), but that is a very large
topic that I don't have time to address here.
Not many MPI results are currently posted, mostly because
the results are obvious -- unless something is very wrong,
the performance of a cluster will be the performance of a
node times the number of nodes. STREAM does not attempt to
measure the performance of the cluster network -- it is only
used to help control the timers.
One benchmark that uses an MPI version of STREAM is the HPC
Challenge Benchmark, targetted at big supercomputing clusters.
The web site is
http://icl.cs.utk.edu/hpcc.
-
Some folks have done their own pthreads implementations.
I can't vouch for these (and will not accept them as "standard"
results unless I can find the motivation to look over the
implementations and convince myself that they are measuring
the same thing as the standard versions).
Second, you need to adjust the problem size so that
the data is not cacheable. You have to add up the caches used by all
the processors that you are going to use.
A Non-Standard Hack:
If you have no threads support and you want to see how bandwidth scales
in a multiprocessor system, you can try the following hack:
-
set up a "background" version of STREAM with a very high value of "ntimes"
(Fortran) or "NTIMES" (C).
-
set up a "foreground" version of STREAM with a normal value for ntimes/NTIMES.
-
start up as many "background" copies as you want
-
start up one "foreground" copy
-
The STREAM bandwidth will be approximately equal to the value for the "foreground"
job times the total number of foreground + background jobs.
Note that results using this hack are not "standard" STREAM benchmark numbers,
and I will not publish them in the tables, but they will give you an idea
of the throughput of the memory system under test.
Adjust the Problem Size
STREAM is intended to measure the bandwidth from main memory. It
can, of course, be used to measure cache bandwidth as well, but that is
not what I have been publishing at the web site. Maybe someday....
-
The general rule for STREAM is that each array must be at
least 4x the size of the sum of all the last-level caches used in the run,
or 1 Million elements -- whichever is larger.
So, for a uniprocessor machine with a 256kB L2 cache (like an older
PentiumIII, for example), each array needs to be at least 128k elements.
This is smaller than the standard test size of 2,000,000 elements, which
is appropriate for systems with 4 MB L2 caches. There should
be relatively little difference in the performance of different sizes once
the size of each array becomes significantly larger than the cache size,
but since there are some differences (typically associated with TLB reach),
for comparability I require that results even for small cache machines
use 1 million elements whenever possible. This requires only 22 MB,
so it should be workable on even a 32 MB machine.
If this size requirement is a problem and you are interested in submitting
results on a system that cannot meet this criterion, e-mail
me and we can discuss the issues.
For an automatically parallelized run on (for example) 16 cpus, each
with 8 MB L2 caches, the problem size must be increased to at least N=64,000,000.
This will require a lot of memory! (about 1.5 GB). If you get much bigger
than this, you will need to compile with 64-bit addressing. For systems using the 64-bit
extensions to the x86 instruction set you will need to use 64-bit pointer
offsets using the compiler flag "-mcmodel=medium". Once N exceeds 31 bits
(slightly over 2 billion), you will need to be sure to use 64-bit integers. This
is automatically handled by stream.c on 64-bit systems -- I have not yet upgraded the Fortran
version to ensure that it will handle such large cases correctly.
What about the "tuned" category?
The "tuned" category has been added to allow users or vendors to submit results based
on modified source code. The benchmark is required to maintain the data flow of the
original source code (to prevent compilers from optimizing away the benchmark).
For C code, the standard "stream.c" contains a C preprocessor variable "TUNED"
which, if defined, will cause the code to call separate functions to perform each
of the four kernels. For Fortran, an analogous example is provided at
sample harness
If you submit "tuned" results, please provide a brief explanation of the tuning
approach. In some cases I might have more questions, but it is generally quite easy
to determine whether the results are plausible on the platform under test.
The purpose here is not to be picky -- I am mostly concerned that the
changes do not accidentally defeat the purpose of the benchmark.
This category explicitly allows assembly-language coded kernels. I put the kernels
inside separate subroutines to make this more convenient.
Who is responsible for STREAM?
STREAM was created and is maintained by
John
McCalpin, john@mccalpin.com.
NOTICE and DISCLAIMER
The STREAM benchmark was developed while McCalpin was on the faculty at
the University of Delaware. After three years at
SGI,
six years at
IBM,
and three years at
AMD,
I am now employed by the
Texas Advanced Computing Center
at the
University of Texas at Austin,
where I work on on performance analysis of applications on TACC's
major systems, and on technology issues related to advanced and novel
computing architectures. The STREAM benchmark
remains an independent academic project, which will not be
influenced or directed by commercial concerns. In order to maintain
this independence, the STREAM benchmark is hosted here at U.Va. under
the sponsorship of
Professor
Alan Batson and Professor
William Wulf.
How can I help?
Contributions are always welcome!!!!
STREAM has become a useful and important benchmark because lots of results
are available. Please help us keep up with this rapidly changing market.
If you have access to a new machine that is not listed here, give STREAM
a try!
(See the
Archives
for the source code and comma-delimited database files with the raw data
in them.)
Citing STREAM
Papers citing the STREAM Benchmark in general should refer to:
- McCalpin, John D., 1995: "Memory Bandwidth and Machine Balance in Current
High Performance Computers", IEEE Computer Society Technical Committee
on Computer Architecture (TCCA) Newsletter, December 1995.
I do not have a link to the published version of the paper, but the
submitted version is available.
Papers citing specific STREAM benchmark results that are published at this site should (also)
include a reference such as:
- McCalpin, John D.: "STREAM: Sustainable Memory Bandwidth in High Performance Computers",
a continually updated technical report (1991-2007), available at: "http://www.cs.virginia.edu/stream/".
BibTex versions of the citations:
@ARTICLE{McCalpin1995,
author = {John D. McCalpin},
title = {Memory Bandwidth and Machine Balance in Current High Performance
Computers},
journal = {IEEE Computer Society Technical Committee on Computer Architecture
(TCCA) Newsletter},
year = {1995},
pages = {19--25},
month = dec,
abstract = {The ratio of cpu speed to memory speed in current high-performance
computers is growing rapidly, with significant implications for the
design and implementation of algorithms in scientific computing.
I present the results of a broad survey of memory bandwidth and machine
balance for a large variety of current computers, including uniprocessors,
vector processors, shared-memory systems, and districuted-memory
systems. The results are analyzed in terms of the sustainable data
transfer rates for uncached unit-stride vector operation for each
machine, and for each class.},
pdf = {http://tab.computer.org/tcca/NEWS/DEC95/dec95_mccalpin.ps}
}
@TECHREPORT{McCalpin2007,
author = {John D. McCalpin},
title = {STREAM: Sustainable Memory Bandwidth in High Performance Computers},
institution = {University of Virginia},
year = {1991-2007},
address = {Charlottesville, Virginia},
note = {A continually updated technical report.
http://www.cs.virginia.edu/stream/},
url = {http://www.cs.virginia.edu/stream/}
}
Future Directions for STREAM?
Extensions of the STREAM benchmark for the future are currently being considered.
The main issues that need to be addressed are:
-
Memory Hierarchies: STREAM needs to be extended to measure bandwidths at
each level of the memory hierarchy.
-
Latency: Bandwidth and Latency are a powerful pair of descriptors for memory
systems -- Latency measurements should be added.
-
Access Patterns: Currently STREAM measures only unit-stride performance.
This is easy and sensible, but non-unit stride and irregular/indirect performance
are an important piece of the memory system performance picture.
-
Locality: Many new machines are being developed with physically distributed
main memory. STREAM may be enhanced to measure bandwidth/latency between
"nodes" of distributed shared memory systems.
A "second-generation" STREAM benchmark (STREAM2) is being evaluated, with
the source code and some results available at the STREAM2
page. STREAM2 emphases measurements across all levels of
the memory hierarchy, and tries to focus on the difference between read
and write performance in memory systems.
Counting Bytes and FLOPS
It may be surprising, but there are at least three different ways to count
Bytes for a benchmark like STREAM, and unfortunately all three are in common
use!
The three conventions for counting can be called:
-
"bcopy" counts how many bytes get moved from one place in memory to another.
So if it takes your computer 1 second to read 1 million bytes at
one location and write those 1 million bytes to a second location, the
resulting "bcopy bandwidth" is said to be "1 MB per second".
-
"STREAM" counts how many bytes the user asked to be read plus how many
bytes the user asked to be written. For the simple "Copy" kernel,
this is exactly twice the number obtained from the "bcopy" convention.
Why does STREAM do this? Because 3 of the 4 kernels do arithmetic,
so it makes sense to count both the data read into the CPU and the data
written back from the CPU. The "Copy" kernel does no arithmetic,
but I chose to count bytes the same way as the other three.
-
"hardware" may move a different number of bytes than what the user specified.
In particular, most cached systems perform what is called a "write allocate"
when a store operation misses the data cache. The system loads
the cache line containing the data before overwriting it.
Why does it do this?
It does it so that there will be a single copy of the cache line in
the system for which all the bytes are current and valid. If
you only wrote 1/2 the bytes in the cache line, for example, the result
would have to be merged with the other 1/2 of the bytes from memory.
The best place to do this is in the cache, so the data is loaded there
first and life is much simpler.
The table below shows how many Bytes and FLOPs are counted in each iteration
of the STREAM loops.
The test consists of multiple repetitions of four the kernels, and
the best results of (typically) 10 trials are chosen.
------------------------------------------------------------------
name kernel bytes/iter FLOPS/iter
------------------------------------------------------------------
COPY: a(i) = b(i) 16 0
SCALE: a(i) = q*b(i) 16 1
ADD: a(i) = b(i) + c(i) 24 1
TRIAD: a(i) = b(i) + q*c(i) 24 2
------------------------------------------------------------------
So you need to be careful comparing "MB/s" from different sources.
STREAM always uses the same approach, and always counts only the bytes
that the user program requested to be loaded or stored, so results are always
directly comparable.
