Research
Our group is engaged in cutting edge research of user behavior analysis and modeling, generative modeling of user-generated data, and online interactive learning with users.
Research Topics
- Joint Analysis of Text and Behavior Data +
- Yuling Shi, Zhiyong Peng and Hongning Wang. Modeling Student Learning Styles in MOOCs. The 26th International Conference on Information and Knowledge Management, p979-988, 2017. (PDF)
- Renqin Cai, Chi Wang and Hongning Wang. Account for Correspondence in Commented Data. The 40th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2017), p365-374, 2017. (PDF)
- Derek Wu and Hongning Wang. ReviewMiner: An Aspect-based Review Analytics System. The 40th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2017), p1285-1288, 2017. (PDF)
- Hongning Wang, Rui Li, Milad Shokouhi, Hang Li, and Yi Chang. Search, Mining, and Their Applications on Mobile Devices: Introduction to the Special Issue. ACM Transactions on Information Systems (TOIS), special issue, 2017. (PDF)
- Sarah Masud Preum, Abu Sayeed Mondol, Meiyi Ma, Hongning Wang and John A. Stankovic. Preclude: Conflict Detection in Textual Health Advice. The 15th IEEE International Conference on Pervasive Computing and Communications (PerCom 2017), p286-297, 2017. (PDF)
- Asif Salekin, Hongning Wang, Kristine Williams and John Stankovic. DAVE: Detecting Agitated Vocal Events. IEEE 2nd International Conference on Connected Health: Applications, Systems and Engineering Technologies (IEEE CHASE 2017), p157-166, 2017. (PDF)
- Lin Gong, Benjamin Haines and Hongning Wang. Clustered Model Adaptation for Personalized Sentiment Analysis. The 26th International World Wide Web Conference (WWW 2017), p937-946, 2017. (PDF)
- Lin Gong, Mohammad Al Boni and Hongning Wang. Modeling Social Norms Evolution for Personalized Sentiment Classification. The 54th Annual Meeting of the Association for Computational Linguistics (ACL'2016), p855-865, 2016. (PDF)
- Md Mustafizur Rahman and Hongning Wang. Hidden Topic Sentiment Model. The 25th International World-Wide Web Conference (WWW'2016), p155-165, 2016. (PDF)
- Mohammad Al Boni, Keira Qi Zhou, Hongning Wang and Matthew S. Gerber. Model Adaptation for Personalized Opinion Analysis. The 53th Annual Meeting of the Association for Computational Linguistics (ACL'2015), p769-774, 2015. (PDF)
- Task-based Online Interactive Decision Optimization +
- Qingyun Wu, Hongning Wang, Liangjie Hong and Yue Shi. Returning is Believing: Optimizing Long-term User Engagement in Recommender Systems. The 26th International Conference on Information and Knowledge Management (CIKM 2017), p1927-1936, 2017. (PDF)
- Huazheng Wang, Qingyun Wu and Hongning Wang. Factorization Bandits for Interactive Recommendation. The Thirty-First AAAI Conference on Artificial Intelligence (AAAI 2017), p2695-2702, 2017. (PDF, Supplement)
- Huazheng Wang, Qingyun Wu and Hongning Wang. Learning Hidden Features for Contextual Bandits. The 25th ACM International Conference on Information and Knowledge Management (CIKM 2016), p1633-1642, 2016. (PDF)
- Qingyun Wu, Huazheng Wang, Quanquan Gu and Hongning Wang. Contextual Bandits in A Collaborative Environment. The 39th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR'2016), p529-538, 2016. (PDF)
- Collaborative Sensing: An Approach for Immediately Scalable Sensing in Buildings +
- Nipun Batra, Yiling Jia, Hongning Wang, and Kamin Whitehouse. Transferring Decomposed Tensors for Scalable Energy Breakdown across Regions. The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI 2018), (to appear).
- Nipun Batra, Hongning Wang, Amarjeet Singh and Kamin Whitehouse. Matrix Factorisation for Scalable Energy Breakdown. The Thirty-First AAAI Conference on Artificial Intelligence (AAAI 2017), p4467-4473, 2017. (PDF)
- Cyber Physical Mappings - Empower Building Analytics at Scale +
- Dezhi Hong, Hongning Wang, Jorge Ortiz and Kamin Whitehouse. The Building Adapter: Towards Quickly Applying Building Analytics at Scale. ACM BuildSys 2015, p123-132, 2015. (PDF)
- Dezhi Hong, Hongning Wang and Kamin Whitehouse. Clustering-based Active Learning on Sensor Type Classification in Buildings. The 24th ACM International Conference on Information and Knowledge Management (CIKM'2015), p363-372, 2015. (PDF)
- Privacy-Preserving Personalization +
- Wasi Ahmad, Md Masudur Rahman and Hongning Wang. Topic Model based Privacy Protection in Personalized Web Search. The 39th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR'2016), p1025-1028, 2016. (PDF)
Research Description: Humans are both producers and consumers of Big Data. Modeling the role of humans in the process of mining Big Data is thus critical for unleashing the vast potential of mined knowledge in various important domains such as health, education, security, and scientific discovery. The objective of this research is to build a human-centric learning framework, which harnesses the power of human-generated Big Data with computational models.
We believe that the human-generated natural language text data and interactive behavior data are not random nor isolated, but governed by their underlying intentions. In this research, we develop probabilistic generative models to jointly model text data and various types of behavior data of humans. In addition, we further enhance our assumption as: at micro-level, humans' behaviors are governed by their own intentions; but at macro-level, they are influenced by each other, i.e., social dynamics and social norms. We place our analyses under the context of social influence and explicitly model the interaction among humans during the data generation process. Figure 1 illustrates the basic idea of this research.
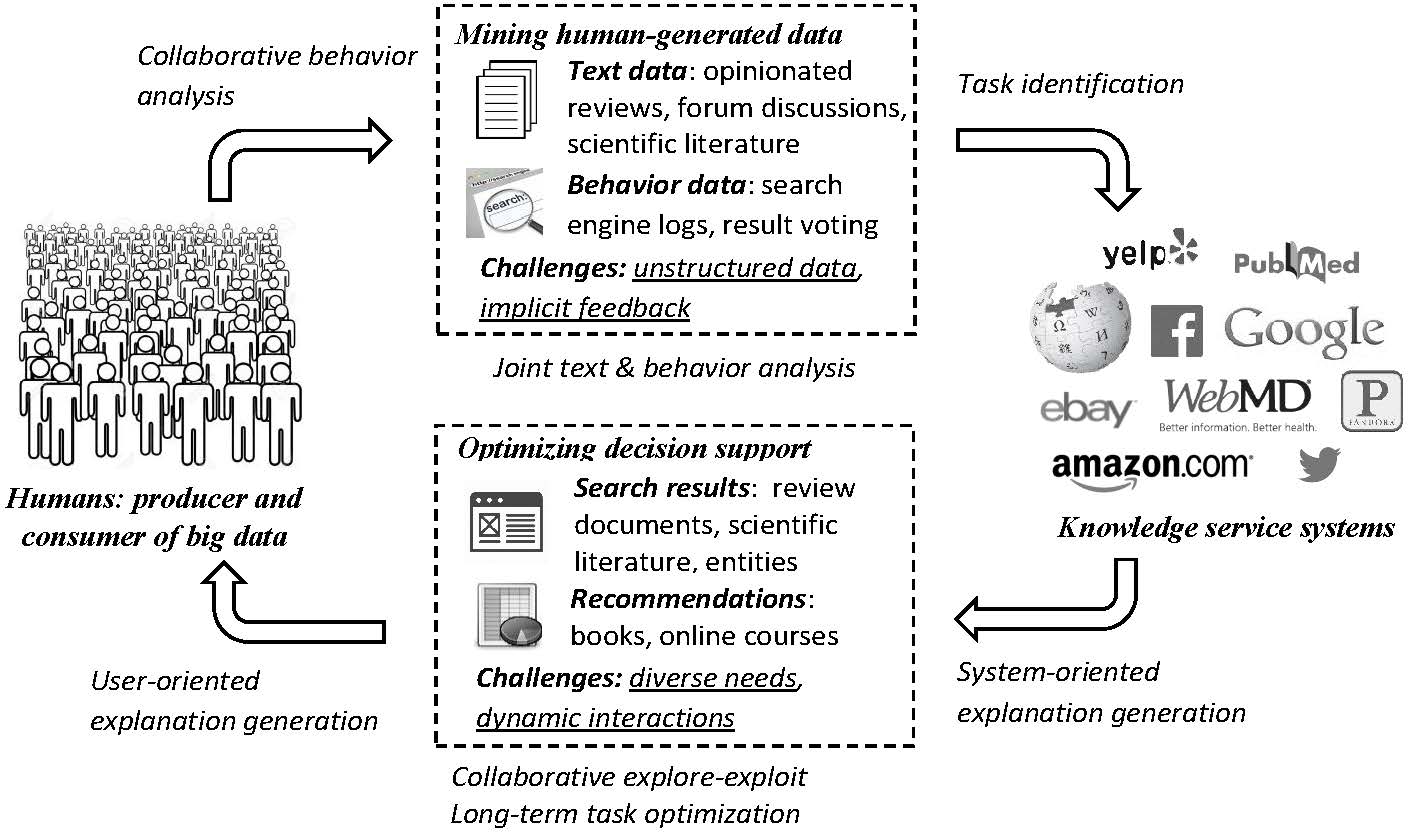
Figure 1. Human-centric knowledge discovery and decision optimization. In this loop, improved systems' utilities can be produced by in-depth understanding of humans (i.e., the flow from humans to systems); and optimized humans' decision making can be realized by customized knowledge services (i.e., the flow from systems to humans).
Team Members: Lin Gong, Lu Lin, Yuling Shi, and Hongning Wang
Collaborators: Md Mustafizur Rahman, Renqin Cai, Jiachuan Deng, Zuo Li and Benjamin Haines
Sponsor: NSF - CAREER: Human-Centric Knowledge Discovery and Decision Optimization
Publications
Research Description: Traditional static, ad-hoc and passive machine-human interactions are inadequate to optimize humans' dynamic decision making processes. To address this limitation, users' longitudinal information seeking activities are organized into tasks, where new online learning algorithms are applied to proactively infer users' intents and adapt the systems for long-term utility optimization.
The assumption about the non-stochastic nature of human behaviors can be further enhanced when we take a longitudinal view: they are executed in such an order to fulfill the underlying goal; and such behaviors might be systematically affected by a system's output during the interaction. In this research, we first organize users' interactive activities into tasks, and then perform online optimization of a system's decision support to achieve long-term optimality for both humans and systems. In particular, we aim at developing a set of algorithmic solutions to perform online learning in a collaborative environment, where the feedback to the learning agents is assumed to be interrelated, noisy and with non-negligible cost. Figure 2 illistrates the idea of interactive online learning with user.
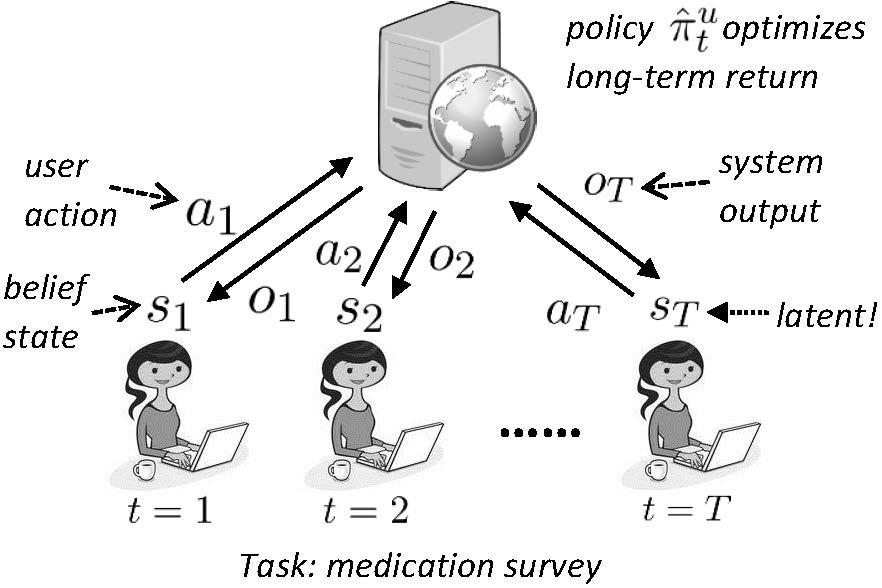
Figure 2. Task-based interactive online learning with users. The learning agent takes real-time feedback from user to update its interaction strategy for long-term optimality.
Team Members Qingyun Wu, Huazheng Wang and Hongning Wang
Collaborators: Quanquan Gu
Sponsor: NSF - III: Small: Collaborative Learning with Incomplete and Noisy Knowledge
Publications
Research Description: Buildings are complex Cyber-Physical Systems with profound impact on human health, productivity, comfort, and energy consumption. Smart building technology promises to improve many aspects of building operation by collecting and analyzing sensor data to support informed and precise building operation. However, adoption of smart building applications is inhibited by the fact that new sensors must be installed in every building.
This research aims to improve the scalability of smart building applications by developing new techniques called collaborative sensing: estimating the sensor data of one building based on sensor data collected in other buildings. The basic premise is that common design and construction patterns for buildings create a repeating structure in their sensor data. Thus, a sparse sensing basis can be used to represent sensor data from a broad range of buildings. A model of a building can be constructed from this sensing basis using only a small amount of data, such as utility meter readings, climate zone, and square footage. This low-dimensionality model can then be used to reconstruct sensor data for the building based on high-fidelity data collected in other buildings. This approach aims to create a shift to a new paradigm in which smart building functionality can be applied to new buildings without the need to install specialized instrumentation. Preliminary testing using publicly available sub-metering data from 100's of buildings indicate that this approach is not only more scalable but also sometimes more accurate than state-of-the-art alternatives. Figure 4 shows the overall idea of collaborative sensing.
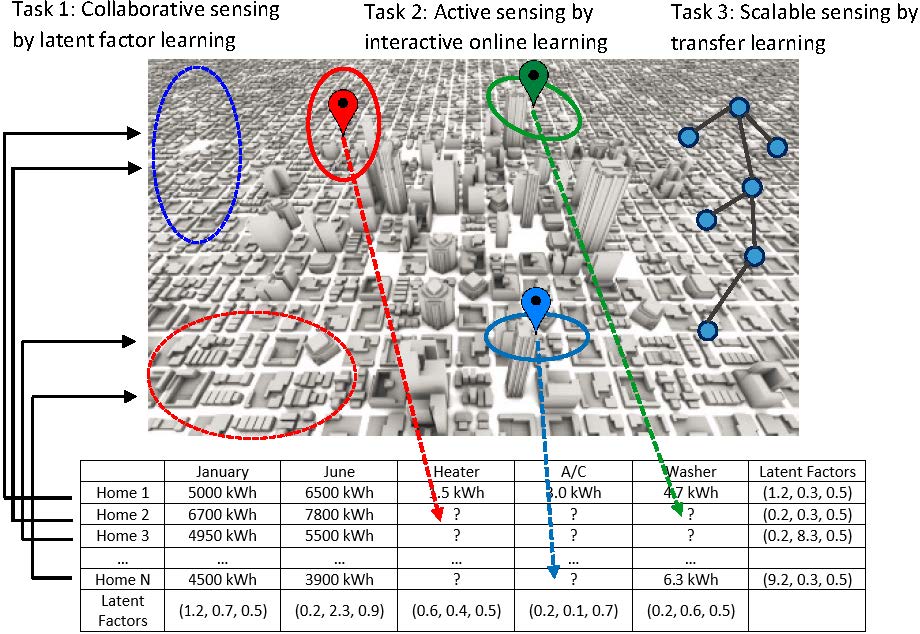
Figure 3. Collaborative sensing: produce an energy breakdown for a target building based on sub-metering data collected in other similar buildings.
Team Members: Nipun Batra, Yiling Jia, Hongning Wang and Kamin Whitehouse
Collaborators: Kamin Whitehouse
Sponsor: NSF - CPS: TTP Option: Breakthrough: Collaborative Sensing: An Approach for Immediately Scalable Sensing in Buildings
Publications
Research Description: Buildings are complex Cyber-Physical Systems that have profound impact on human health, productivity, comfort, and energy consumption. For example, building operation is the single largest energy consumer in the US, accounting for 70% of electricity consumption and 40% of total energy consumption. Allergens, noise levels, and the availability of sunlight affect health and well-being, especially given that on average Americans spend 90% of their time in buildings. Indoor conditions such as thermal comfort and CO2 and pollutant concentrations have been shown to affect human productivity by 8-11%, which has an important effect on the national economy.
The performance of the nation's buildings can be significantly improved with analytics engines that collect and analyze data from the thousands of sensing and control points that already exist within a typical building. However, data alone does not inherently have any meaning, and so a person must manually provide the context – also called metadata – about every sensor and controller so that the analytics engine can interpret the data. This costly manual process can take days or weeks for a single building and is a major obstacle for applying building analytics to a large number of buildings.
The goal of this project is to create a suite of automated cyber-physical mapping solutions that will allow an advanced analytics engine to quickly connect to and analyze the data from a new and unfamiliar building. To achieve this, the it will produce new techniques for metadata inference that automatically infer the metadata of data stream, such as the type of sensor or controller that produced the data and its relation to other sensors, equipment, or rooms in the building. This approach is based on the hypothesis that time series data in buildings is sparse due to the fact that many points have common context such as weather patterns or equipment operation patterns. The contextual information itself is also very structured due to the fact that common design practices create repeated patterns in buildings around the world, such as spatial layout and mechanical equipment. Metadata inference exploits this sparsity and structure to quickly and easily create new metadata values for a large number of sensing and control points. If successful, these techniques will generalize to other types of Cyber-Physical Systems such as human health monitoring, infrastructure monitoring, or smart transportation systems where structure and data sparsity can be used to automatically infer the physical context of a sensor or controller.
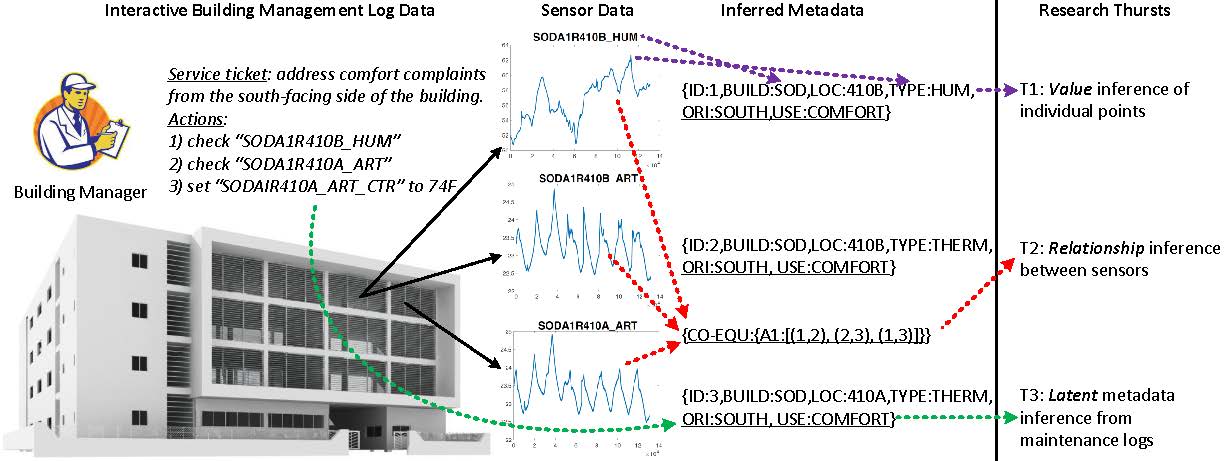
Figure 4. Metadata Inference draws on three data sources: 1) point names (center), 2) raw time series data (center), and 3) search and access patterns (left). The goal is to create new metadata information for each point (right). Values, such as building name, sensor type, and relationship between sensors, such as sharing the same control equipmentp, can be automatically inferred by matching structure in the time series data with structure in the point names. New values such as room orientation or the usefulness of a point can be inferred by matching structure in the time series with structure in the maintenance logs.
Team Members Dezhi Hong, Renqin Cai, Kamin Whitehouse and Hongning Wang
Collaborators: Trane Inc.
Sponsors: NSF - III: Small: Cyber Physical Mappings - Empower Building Analytics at Scale, and the U.S. Department of Energy - The Building Adapter: Automatic Mapping of Commercial Buildings for Scalable Building Analytics.
Publications
Research Description: Most existing efforts in online privacy protection have been focused on protecting the identifiability aspect of privacy (i.e., who issued the inquiry) by using secure communication and encrypted storage in security community. This research concerns another important aspect of privacy: linkability. Linkability is what enables a provider to link multiple queries to the same user, and thereby learn detailed profiles about a user's interests and behaviors. A system with statistical inference mechanisms can largely decipher users' identities and their underlying intentions from simple observations of their information seeking behaviors. This leaves users with little control to avoid "curious" systems abusing their personal information, e.g., digital discrimination, or even to be aware of the abuse, given such information is already on the server side.
In this research, algorithmic solutions will be developed to protect the linkability aspect of privacy based on our adversarial assumption motivated from an economics perspective. On the user side, personalization is achieved by modeling each user as a probabilistic mixture over a set of latent groups to facilitate customizing the results. On the server side, without other external knowledge, a service provider can at most recognize a user's underlying intents at the group-level from its distorted observations of users' queries and clicks. By modeling users' long-term interactive behaviors as tasks and applying the proposed generative model in an online fashion, balance between privacy and personalization can be dynamically adjusted with respect to their sequential feedback in the long run. A testbed based on public data sets and new evaluation metrics will be developed to assess the practical value of the developed algorithms for privacy-preserved personalization. Figure 3 demonstrates the basic workflow of privacy protection developed in this research.
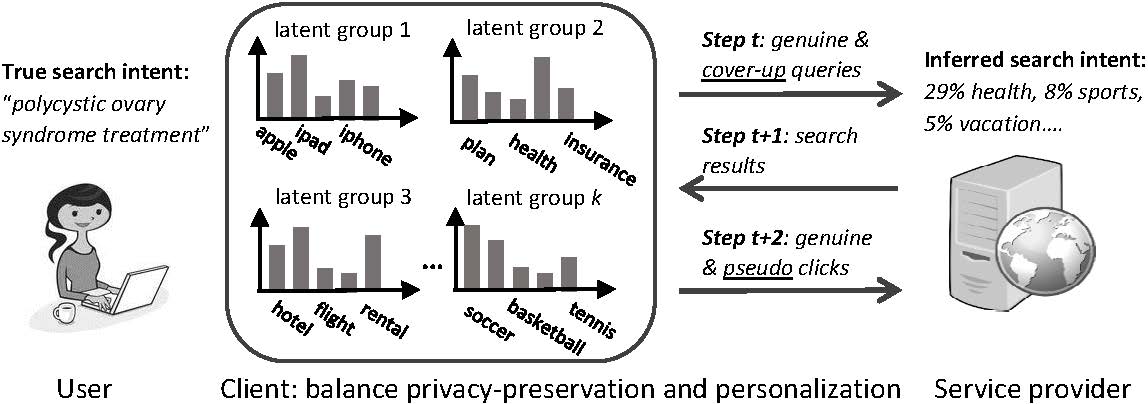
Figure 5. Privacy-preserving personalization: users' search behaviors are modeled with a generative mixture model on the client side, which obfuscates users' search intents in a probabilistic way.
Team Members Wasi Uddin Ahmad (UCLA), Kai-Wei Chang (UCLA), Puxuan Yu (Wuhan University) and Hongning Wang
Collaborators: Denis Nekipelov and David Evans
Sponsor: The University of Virginia School of Engineering and Applied Science Cyber-security Projects Initiative
Publications