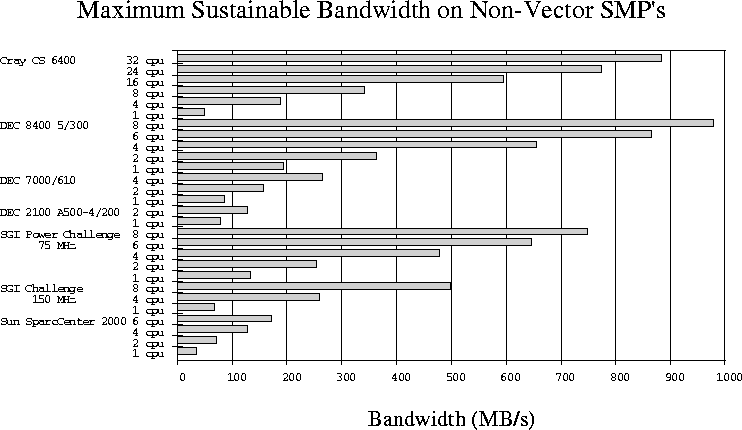
RISC-based, shared-memory, symmetric multiprocessor (SMP) machines are perhaps the most rapidly growing component in the high performance computing market. Sustainable memory bandwidth for a variety of these machines is presented in Figure 3.
Figure 3: Sustainable memory bandwidth for non-vector shared-memory
systems. The value shown is the maximum of the four STREAM tests.
Note that the full scale is only 3% of the full scale of Figure 1 and only 1/120th of the full scale of Figure 2! To simplify the presentation, only the fastest of the four STREAM memory bandwidth numbers is presented for each configuration.
In contrast to the non-blocking memory interfaces on the the vector shared-memory machines, these RISC-based shared memory machines are all bus-based. These systems all use a split-transaction model on the bus to allow efficient use of the limited bandwidth in the presence of high latencies. On the SGI Power Challenge, for example, a single processor executing a ``copy'' operation only utilizes 16% of the bus bandwidth. The remainder is available for other cpus, and it is fairly well utilized, with 8 cpus moving over 1120 MB/s (counting the write allocate traffic) -- which is about 94% of the peak theoretical bus bandwidth.
Although these machines show relatively good scaling, it can be argued that this scaling is only good because the per-node performance is so low that it does not strain the bus. It is interesting to note that the IBM RS/6000-990 (a uniprocessor server) has a ``triad'' bandwidth of over 700 MB/s, exceeding all but a few of the largest machine configurations from Figure 3.
To the extent that applications are memory bandwidth limited on these machines, one can use parallelism as a form of ``latency tolerance'' (i.e., work can continue on processor B while processor A is stalled waiting for cache line fills). It should be clear that this approach is an expensive way to obtain memory bandwidth. It seems likely that it would be more efficient to have extra special-purpose load/store units to stall on cache misses, rather than entire cpus. This is the approach taken by the IBM Power 2 processor, and by many new processors which, while having only a single load/store unit, support non-blocking caches (which can be considered a sort of ``split transaction'' model at the cache controller level).