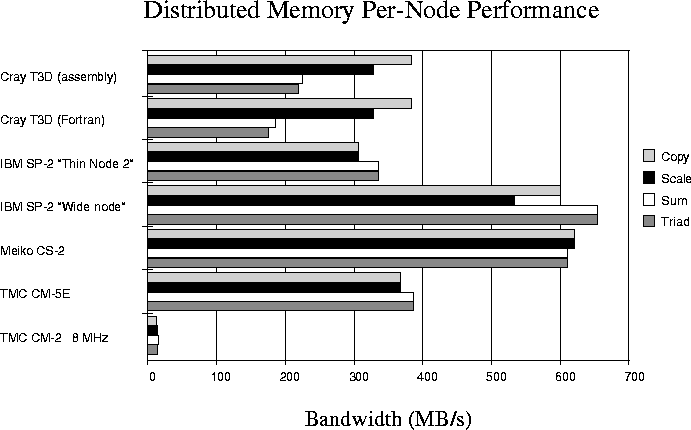
Parallel scaling of STREAM memory bandwidth is essentially perfect on distributed memory machines, so only single-node results are presented in Figure 6.
Figure 6: Part 2: Sustainable memory bandwidth for a single node
of several distributed memory computers. The CM-2 result
is for the ``slicewise'' model, for which 32 single-bit
processors plus one vector unit is considered one node.
The IBM SP-2 results are inferred from the performance
of the IBM workstations with identical cpu and bus
configurations.
Note that the IBM SP-2 results are inferred from workstation results with identical cpu and memory bus specifications -- caveat emptor.
Some very interesting performance features are evident in these results, especially those of the Cray T3D. The most obvious feature is that the two-operand tests (``copy'' and ``scale'') are considerably faster than the three-operand tests (``sum'' and ``triad''). On investigation, it is found that this is because the memory system on the T3D can write significantly faster than it can read. Details are presented in Appendix A.
It is also interesting to note that the Cray T3D has much higher sustainable memory bandwidth values than any of the workstations, servers, or shared-memory systems employing the DEC 21064 processor, and it actually outperforms even the newer systems based on the DEC 21164 processor.